LLM 范式重构电商推荐召回:生成式召回的工程实践全记录
本文整理自某大型电商推荐系统内部技术文档,记录了在商城推荐召回阶段引入 LLM 训练范式(Foundation Model + Generative Recall)的完整工程实践。核心方案以 Pretrain → Posttrain → SFT 三阶段训练为框架,将召回链路从判别式改为生成式(Beam Search),并首次走通 Foundation Model 参数加载范式,最终在真实电商场景取得 GMV +0.374%、训练时间 49.8 天 → 12.3 天 的效果。
0. 背景:推荐系统的两个结构性局限
“算力 + 通用方法,长期总是胜过精心设计的领域先验”——这是 AI 过去数十年演进反复兑现的规律(Bitter Lesson, Rich Sutton)。从 ImageNet 时代的卷积网络对手工特征的胜利,到 BERT/GPT 系列对结构化 NLP 流水线的颠覆,再到 AlphaZero 仅靠通用强化学习就吊打围棋专家系统——这条规律一次又一次被验证。
推荐系统是这一规律目前尚未被充分兑现的主要方向。过去推荐系统依赖先验的精细化设计在历史阶段带来了可观收益(DIN 的 attention 先验、双塔的 Late Fusion 先验、PLE/MMOE 的多任务 gating 先验等),但当算力与数据规模持续扩展时,整套链路逐渐显现出两个结构性局限:
局限一:算力利用斜率受限
在 Pointwise 预估框架下,单条样本仅提供 1 个监督信号,样本利用效率低。具体来说:传统的 user-item pair 样本,每条样本从 forward 到 backward 全图过一遍,最终只产生一个 binary cross-entropy 监督信号。这种 1:1 的样本-信号比意味着,要让模型学到充分的用户兴趣表征,必须把数据集翻倍、把训练时间拉长。LLM 的序列样本自回归训练一条即可贡献 $L$ 个监督信号(其中 $L$ 是序列长度),样本效率提升 $L$ 倍。换句话说,同样的计算资源,LLM 范式能看更多"东西",能从同一份样本中蒸馏出更多有效信号。
更深层的原因是,LLM 的序列建模天然就是条件概率分解:
$$P(x_1, x_2, \ldots, x_L) = \prod_{t=1}^{L} P(x_t \mid x_{局限二:建模天花板受限
强先验的网络结构和单一化的建模任务,在 GPU 强算力时代成为迭代瓶颈。统一 Transformer 结构的工作(如 OneTrans)已经把网络主干统一化,但其输入输出相对固化——往往只接 user feature group 与 item feature group 两个输入,仅输出一个标量打分。在算力充裕的今天,这种"窄输入、窄输出"的设计已经变成迭代速度的天花板。我们想新增一个上下文特征、想新增一个目标信号、想新增一种建模任务,往往都需要改图、改 reader、改 loss、改 metric——边际成本极高。
通过导入 Action、Context 等输入和相关预测任务,打开了 Transformer 输入输出建模复杂化和通用化的迭代空间。新输入只需要扩展 tokenizer,新任务只需要在序列末尾加 token、在 loss 上加权重——一切都退化为"序列上的 token 增减问题",迭代成本骤降。
生成式召回 vs 判别式召回的本质差异
判别式范式假定召回任务是"在 N 个候选中找 top-K",于是把 user 和 item 分别建模成一个向量,用点积得分排名。这一假定在 N 比较小时还合适,但当商品库规模上亿、user 多兴趣多场景时,就开始捉襟见肘——双塔被迫维持 fixed dimension,无法 scale;user 兴趣被压缩成一个向量后多模态信息丢失;冷启动 item 由于历史交互稀疏导致 embedding 学不出来。
生成式范式则把召回视为"给定上下文,自回归生成 item 序列",本质上更接近自然语言模型的下一词预测。每个 item 被表征为多 token 的语义码字(Semantic ID),模型学到的是一个条件分布 $P(\text{item} \mid \text{user history, context})$,可以直接采样、Beam Search、或者按概率排序——所有这些操作都不依赖商品库的具体规模。
基于上述判断,这次工作做出了一个大胆的尝试:把 LLM 的训练范式完整引入推荐召回阶段,在全场景长周期序列样本上产出 Foundation Model,参数加载到下游召回任务继续 SFT,线上链路通过 Beam Search 的生成式链路替换了原本判别式召回的索引式链路(IVF/HNSW)。
1. 整体方案:三阶段 LLM 训练范式
整个方案以 LLM 的训练范式为基准,在电商商品推荐的召回场景上落地。样本组织形式、训练流程如下:
三个训练阶段
阶段一:Foundation Model Pretrain
在序列样本上进行无监督预训练,采用多层 SID 自回归的建模方式,引入 NTP (Next Token Prediction) Loss 进行预训练,充分学习用户行为模式与商品语义的通用表征。这一阶段覆盖全场景两年历史数据,在 SEA 地区可以做到 2~3 天训完。
Pretrain 的核心目标是让模型学到与下游任务无关的通用表征:用户的多兴趣分布、商品的语义聚类结构、不同场景的行为模式差异。这一阶段不偏向任何特定下游目标(点击 vs 成交、商城 vs 直播间),所以可以无差别地加载到任何下游任务作为初始化。模型规模和数据规模在这一阶段同时扩展,训练成本最高,但收益分摊到多个下游任务后边际成本反而最低——这正是"一次预训练、多场景复用"的工程价值所在。
阶段二:Recall Posttrain
从 Pretrain ckpt load 起训,前缀历史经 Prefill Merge 压成 5× 压缩的 Merged Token,只对末尾 last-k 位置做 Next Multi-Item Predict、按 set-based 样本组织,与召回按 top-K 取集合的使用方式对齐。
Posttrain 是 Pretrain 与下游 SFT 之间的缓冲带:既要保留 Pretrain 学到的通用表征不被破坏,又要适配召回任务"取集合"而非"取序"的语义。具体做法是把 Pretrain 时的 Next Item Predict 切换为 Next Multi-Items Predict,同时收紧训练样本到召回样本——这是一个典型的"任务对齐 + 数据对齐"双重适配过程。
阶段三:Recall Task SFT
召回下游上线任务,延续 Merged 输入作为 prefill,切到 pointwise 样本并用 Single-Token Loss;引入 Reward 增强召回效率。
SFT 阶段把模型彻底对齐到上线任务的目标分布上。Pointwise 样本的引入是必要的——线上召回打分需要 user-item-context 三元组的精细计算,pointwise loss 能让模型学到细粒度的偏好排序。Reward 的引入则借鉴了 RLHF 的思路,用业务指标(GMV、点击率、加购率等)作为奖励信号,让模型直接对齐业务目标而非代理目标。
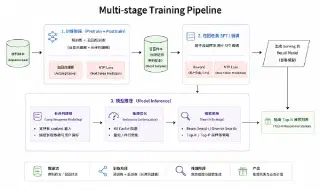
这一范式的核心价值是"一次预训练,多场景复用":
$$\text{Foundation Model} \xrightarrow{\text{Recall SFT}} \text{召回模型} \xrightarrow{\text{Ranking SFT}} \text{粗排/精排模型}$$同时也打开了清晰的 scaling 路径:模型规模、序列长度与训练数据量均可在可观测的收益曲线下持续扩展。多阶段架构的"无损迁移"特性——backbone 不变、仅切换数据组织和 loss——保证了 Pretrain 的成本可以被多个下游任务平摊,训练算力的单位收益最大化。
生成式召回 vs. 传统判别式召回
传统的双塔召回本质是判别式框架:用 User Embedding 和 Item Embedding 的点积估计相关性,用 HNSW/IVF 做近似最近邻检索。这套方案在大量部署下也暴露了若干局限:
| 维度 | 判别式召回(双塔) | 生成式召回(本方案) |
|---|---|---|
| 建模目标 | 点积相似度 | 自回归序列生成 |
| 索引结构 | HNSW/IVF(耦合商品库) | Beam Search(解耦商品库规模) |
| 冷启动 | 弱(依赖 ID 特征) | 强(SID 语义泛化) |
| Scaling | 受限于双塔结构 | 随 LLM 参数量 Scaling |
| 多目标 | 需要多任务改造 | Condition Token 自然支持 |
生成式框架的推理复杂度解耦商品库规模,Scaling 空间更大;Semantic ID 的引入改善了模型泛化能力,冷启动商品的 PV 和点击显著提升。
更深一层看,判别式与生成式的区别本质上是信息处理顺序的差异。判别式先固定商品库规模、再在上面做检索,是"先静态、后查询";而生成式先理解上下文、再让模型生成 item,是"先理解、后生成"。前者把所有学习压力压在 Embedding 上,后者把学习压力分散到整个 Transformer 的所有层和 token 上。当 Embedding 容量遇到瓶颈时,前者的 scaling 曲线开始走平,而后者还能通过加深加宽 Transformer 继续涨——这是为什么"模型规模越大、生成式优势越明显"的根本原因。
2. 模型结构:工业化 LLM Backbone
2.1 整体架构
模型采用标准 Decoder-Only Transformer,本次上线版本选用 170M 参数档位,核心超参如下:
| 配置 | Value |
|---|---|
| Layers | 6 |
| Hidden dim | 4096 |
| FFN dim | 1024 |
| Attention heads | 8 |
| KV heads (GQA) | 4 |
| Head dim | 128 |
| Max sequence length | 1024 |
| SID 码本 | 8192 × 3 |
| 总参数量 | 170M |
核心 Transblock 完全沿用 LLaMA / Qwen 等主流 LLM 的设计(RMSNorm + SwiGLU + RoPE + GQA),并叠加了三项针对深层 Transformer 稳定性的改动。
Decoder-Only 选择的理由:相比 Encoder-Decoder 架构,Decoder-Only 在生成式推荐场景下有几个显著优势:(1) 训练时一条样本同时贡献 L 个监督点(teacher forcing),样本效率最大化;(2) 推理时一次 prefill + 多步 decode,KV cache 可以复用;(3) 同一个模型既能做 Pretrain(Next Token Predict)也能做下游任务(Beam Search 生成),避免了两套结构的迁移损失。
One Transformer 理念的贯彻:同一套 backbone 结构贯穿 Pretrain → Stage-1 Recall PostTrain → Recall SFT&RL 多个训练阶段保持不变,阶段切换只调整数据组织、loss 形式与优化器配置,模型权重可以无损迁移、拼接、复用。这一设计的工程价值不容忽视——它意味着 Pretrain ckpt 可以直接 hot-start 任意下游任务,避免了"换结构就要重新预训练"的浪费;它也意味着在 backbone 维度的所有优化(FlashAttention、混精度、KV cache 共享等)都能跨阶段复用。
与此前判别式召回的对比:
| 参数 | 旧版 DVF 召回 | 本方案(v1) |
|---|---|---|
| 参数量 | 1.3M | 170M |
| FLOPs | 1.41T | 96.33T |
| 序列长度 | 200 | 512 |
参数量提升了约 130 倍,FLOPs 提升了约 70 倍,序列长度从 200 拉长到 512——这并不是"暴力堆资源",而是因为生成式框架的 Scaling 曲线还远未饱和。在双塔架构下,把 1.3M 参数堆到 170M 几乎得不到提升(双塔的 bottleneck 在 embedding 维度而不在网络深度);但在 Decoder-Only 的 LLM 框架下,每一份额外参数都能转化为更精细的兴趣建模、更强的语义泛化能力。
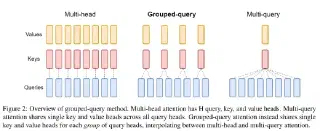
2.2 Grouped Query Attention(GQA)
标准 MHA 下每个 query head 独立维护一套 KV,KV 显存随 head 数线性增长。在 LLM 推理场景下,KV cache 是显存瓶颈的主要来源——当 batch_size、sequence_length、num_heads、head_dim 任意一个维度上升时,KV cache 都成倍增长。具体地,KV cache 的显存占用为:
$$\text{KV cache size} = 2 \times B \times L \times H_{kv} \times D_{head} \times \text{precision}$$其中 $B$ 是 batch、$L$ 是序列长度、$H_{kv}$ 是 KV head 数、$D_{head}$ 是 head 维度。对于一个 batch=2048、L=1024、H=8、D=128、FP16 的模型,仅一层的 KV cache 就需要约 8GB,6 层就是 48GB——这还没算计算时的 attention map 中间值。
MQA(Multi-Query Attention)的缺陷:MQA 把所有 query head 都共享同一组 KV(即 $H_{kv}=1$),KV cache 直接降到 $1/H$,但效果损失明显——当不同 query head 关注的语义模式差异较大时,强制它们共用一组 KV 会丢失重要的多视角注意力。LLaMA 早期实验就发现 MQA 在长序列下有 1-2 个百分点的明显效果退化。
GQA(Grouped-Query Attention)的设计原理:GQA 是 MHA 与 MQA 之间的折中——把 query head 分成若干组,每组共享一套 KV。本方案设置为 8 query head 共享 4 KV head(即 group size = 2),KV 显存降低约 2×。这种设计的精妙之处在于:当不同 query head 之间存在"组内相似性"时(往往如此,因为相邻 head 在训练后会自然学到相近的注意力模式),合并它们的 KV 几乎不损失信息,但能省一半显存。
数学上,GQA 的 attention 计算可以写为:
$$\text{Attn}_{\text{group } g}(Q^{(g)}, K^{(g)}, V^{(g)}) = \text{softmax}\!\left(\frac{Q^{(g)} K^{(g)\top}}{\sqrt{d_{\text{head}}}}\right) V^{(g)}$$其中 $Q^{(g)}$ 表示属于第 $g$ 组的所有 query head 的拼接,$K^{(g)}, V^{(g)}$ 是该组共享的 KV。
实验效果(HR@50 仅 -0.3%,吞吐 +15%):
| 改动 | HR@1 | HR@10 | HR@50 | instance/s |
|---|---|---|---|---|
| Q head 8 / KV head 8 | - | - | - | - |
| Q head 8 / KV head 4 | -0.05% | -0.1% | -0.3% | +15% |
效果损失极小,而推理吞吐提升明显——这种权衡在工业推荐场景下完全可以接受。为什么推荐场景对 GQA 损失更不敏感? 因为推荐序列里大多数 token 都是 SID(语义码字),相比自然语言 token 的语义稀疏性更低、模式更同质,多组 KV 的边际信息相对小一些;同时,推荐模型对 latency 的要求又远高于纯 NLP 服务(线上 QPS 是关键指标),所以"用一点效果换显著吞吐"的 trade-off 在这里非常划算。
2.3 SwiGLU FFN
FFN 采用 SwiGLU,相比 ReLU/GELU 在同等参数规模下有稳定的 loss 改进,也是当前主流 LLM 的默认选择(Noam Shazeer 2020):
$$\mathrm{FFN}(x) = \bigl(\mathrm{SiLU}(xW_{\text{gate}}) \odot xW_{\text{up}}\bigr)W_{\text{down}}$$其中 $\text{SiLU}(x) = x \cdot \sigma(x)$ 是 Sigmoid Linear Unit,与 Swish 等价。SwiGLU 的核心思想是引入 gating 机制——SiLU(xW_gate) 充当门控信号,逐元素地控制 xW_up 哪些维度被激活、激活到什么强度。相比朴素的 ReLU(xW)W' 这种"全有全无"的激活,SwiGLU 的连续门控让信息流动更平滑、梯度更稳定。
SwiGLU FFN 由 gate / up / down 三个矩阵组成,参数量为 $3dm$。标准做法是取 $m = 8d/3 \approx 2.67d$ 以对齐 vanilla FFN 参数预算(vanilla FFN 是 $d \to 4d \to d$,参数量 $8d^2$;SwiGLU 用 $3dm = 3 \times d \times \frac{8d}{3} = 8d^2$ 与之对齐)。但考虑到 L40 + FP16 推理下 Tensor Core 的对齐限制(intermediate size 需为 16 的倍数),本方案将中间层放宽至 $m = 4d$,参数量约为 vanilla 配置的 $1.5\times$。
实验发现增加 FFN 参数量,主要提升了模型对 SID 映射关系的记忆能力(SID Level 2/3 的 hitrate):
| Expand ratio | HR@1 | SID Level 0 HR@1 | SID Level 1 HR@1 | SID Level 2 HR@1 | instance/s |
|---|---|---|---|---|---|
| 2.67d (标准) | - | - | - | - | - |
| 4d (本方案) | +5% | +1% | +8% | +15% | -2% |
SID Level 2 的提升尤其大(+15%)——这印证了一个直觉:FFN 是 Transformer 的"知识库",参数量越大,能记住的细粒度映射关系越多。SID Level 2 是最细粒度的码字(对应商品的差异化特征),需要模型记住"前缀 (s0, s1) 之后到底接哪个 s2"——这种记忆能力恰恰是 FFN 容量决定的。Transformer 注意力层贡献"上下文计算",FFN 层贡献"事实记忆",二者协同决定了模型的整体能力上限。
2.4 RoPE 位置编码
位置编码使用 RoPE(Rotary Position Embedding),通过对 Q/K 直接做相位旋转引入相对位置信息。传统位置编码方案有两种——绝对位置编码(APE)通过 lookup embedding 表给每个位置加偏置;相对位置编码(如 T5 的 relative attention bias)则在 attention logit 上加可学习的偏置矩阵。两种方案各有不足:APE 在长度外推时表现差(训练时没见过位置 1024,推理时遇到就崩),相对位置编码计算开销大且不易并行化。
RoPE 的核心想法是把位置信息编码成"相位旋转"——给定位置 $m$ 和向量 $\boldsymbol{x}$,把 $\boldsymbol{x}$ 按维度两两配对,每对 $(x_{2i}, x_{2i+1})$ 当作复数 $x_{2i} + j x_{2i+1}$,乘以旋转因子 $e^{j m \theta_i}$(即旋转角度 $m\theta_i$)。这样 query 在位置 $m$、key 在位置 $n$ 时,二者的 attention logit 自然包含相对位置 $m - n$ 的信息:
$$\langle \text{RoPE}(\boldsymbol{q}, m), \text{RoPE}(\boldsymbol{k}, n) \rangle = \boldsymbol{q}^\top R_{m-n} \boldsymbol{k}$$其中 $R_{m-n}$ 是相对位置 $m-n$ 决定的旋转矩阵——这意味着 logit 只与相对位置有关,与绝对位置无关,天然支持任意长度外推。
RoPE 在生成式推荐中的特殊价值:序列长度在不同阶段差异明显——Pretrain 用 512、Recall Posttrain 切换到 prefill merge 后等效更短、Beam Search 推理时随着生成步数序列还会增长。RoPE 让结构在不同长度下都可以直接复用,无需额外训练。如果用 APE,每次切换序列长度都要重训 position embedding;用相对位置 bias 又会拖慢推理。RoPE 是这两难之间的最优解。
对异构 token 的处理:推荐序列中 token 类型不同——有 Context token(场景标签)、有 SID token(商品语义码字)、有 Item info token(商品 ID 等精细特征)。这些 token 的位置信息含义完全不同——Context token 之间是无序的标签集合、SID token 之间有强次序关系(粗到细的语义分级)、Item info token 仅作为辅助补充。本方案把所有 token 类型的位置都按"全炸开"方式编码(每个 token 占一个完整位置),让 RoPE 同时学到"序列级位置"和"层级关系"。
Pretrain 阶段对比 APE 和 RoPE 的实验结果(RoPE 对异构 token 全炸开的形式提升最大):
| 位置编码 | HR@1 | HR@10 | HR@50 |
|---|---|---|---|
| NoPE | - | - | - |
| APE | +5% | +6.2% | +8.3% |
| RoPE | +10% | +12% | +18% |
注意 NoPE 也并非完全没有位置感知——Decoder-Only 的 causal mask 本身就隐含了"当前 token 只能看到前面 token"的弱位置信息。但这种弱位置信息不足以建模复杂序列,加了 APE 提升一档,加了 RoPE 再提升一档。RoPE 对长序列尤其友好——HR@50 提升 18% 远高于 HR@1 的 10%,说明 RoPE 在"远程上下文"的建模上更有优势。
2.5 稳定性三件套
深层 Transformer 在 scaling up 过程中频繁出现方差失配问题:不同模块输出方差量级不对齐,导致激活爆炸、attention logit 过大、残差路径失效。当模型从 1B 走向 100B 时,这些问题会被指数放大,最终训练直接 NaN。即便是 170M 这样的中小模型,只要层数 ≥ 6、序列长度 ≥ 512,方差失配的隐患就已经显现。以下三项措施协同控制稳定性:
QK Norm
序列长度和 d_model 同时上升后,attention logit $QK^T/\sqrt{d_\text{head}}$ 的量级波动显著加剧。具体来说,$Q$ 和 $K$ 是从同一个 hidden 投影出来的,两者方差成正相关,而 $QK^\top$ 是它们的内积——方差按 $d_{\text{head}}$ 的量级累积。即便除以 $\sqrt{d_{\text{head}}}$,logit 的尾部分布仍然会有少量极大值,softmax 之后就退化为 one-hot——某个 query 100% 关注某个 key、其它 key 完全得不到 attention,梯度几乎全集中在那一对 (Q, K) 上,训练极不稳定。
在 Q、K 投影之后套一层 RMSNorm(QK Norm),归一化后 logit 的尺度收敛到固定范围,softmax 梯度分布更均匀。具体形式:
q = self.q_proj(x)
k = self.k_proj(x)
q = self.q_norm(q) # RMSNorm
k = self.k_norm(k) # RMSNorm
attn = (q @ k.transpose(-1, -2)) / sqrt(d_head)
QK Norm 强制 $\|Q\|_2$ 和 $\|K\|_2$ 都被归一化到固定模长,logit 的最大可能值被严格限制在 $\|Q\|\|K\|/\sqrt{d_{\text{head}}}$ 之内,再也不会出现极端值。
同时去掉了之前大量使用的 Kernel Norm,加上 weight decay 配合 QK Norm 一起稳定训练。实验验证,这个替换还可以顺带去掉模型中所有的 bias,既节省计算量又提升性能。为什么去 bias 是合理的? 因为 RMSNorm 本身会做尺度归一化,bias 的偏移功能可以被下游层的 weight 等效吸收——保留 bias 反而引入冗余自由度,让训练更难收敛。
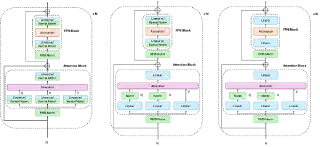
Residual Rescale
Pre-Norm 结构下每层的残差 $y = x + F(x)$ 会让 $\text{Var}[x]$ 单调上升。具体地,假设每层的 $F(x)$ 输出方差为 $\sigma^2$,且与 $x$ 不相关,则:
$$\text{Var}[y] = \text{Var}[x] + \text{Var}[F(x)] = \text{Var}[x] + \sigma^2$$经过 $L$ 层后,$\text{Var}[x_L] = \text{Var}[x_0] + L\sigma^2$,方差线性增长。当 $L$ 很大(比如 $L=24$ 的 GPT-2 small)时,深层的 $\text{Var}[x_L]$ 远大于浅层,使得后面层的 attention/FFN 的 norm input 几乎已经被前面层的累积残差主导——新增的 $F(x_L)$ 相对于 $x_L$ 来说是噪声级的,网络深度带来的实际表达力急剧衰减。
参考 DeepNorm/GPT-2 的做法,把残差分支按深度衰减,每层残差缩到原来的 $1/\sqrt{2L}$:
self.residual_scale = 1 / math.sqrt(2. * self.layer)
attn_out = self.attn(norm(x))
x = x + self.residual_scale * attn_out
mlp_out = self.ffn(norm(x))
x = x + self.residual_scale * mlp_out
每层引入的增量方差为 $O(1/L)$,$L$ 层累计后整体方差保持常数量级。实测没有 Residual Rescale 的话,模型层数大于 6 就很容易训崩。
这个看似简单的 $1/\sqrt{2L}$ 系数,背后是对深层网络方差累积问题的精细控制。它和 LayerNorm/RMSNorm 不是替代关系,而是协同关系——norm 控制每层输出的方差水平,rescale 控制方差的累积速率,二者一起让深层 Transformer 能稳定训练到更深的层数。
Softcap
个别 token pair 上极端偏大的输出会让下游激活饱和、梯度回传不稳,FP16/BF16 训推下尤其敏感。FP16 的最大可表示数是 $\pm 65504$,BF16 虽然指数位更宽(最大约 $3.4 \times 10^{38}$),但精度位只有 7 位,乘加链路上的微小误差很容易被放大成大数。一旦激活值溢出为 inf,整张图的梯度都会变成 NaN,训练直接崩溃。
在 attention 子层和 FFN 子层输出加一层 tanh soft cap:
def _soft_capping(self, x):
return self.softcap * tf.math.tanh(x / self.softcap)
Softcap 在 $|x| \ll \text{softcap}$ 区域接近恒等(因为 $\tanh(x/c) \cdot c \approx x$ 当 $x$ 小),超出后平滑收敛到 $\pm\text{softcap}$。相比硬截断(clip)它可导,梯度不会突然变 0;相比直接限幅,它在饱和区附近还有一定的梯度信号能传回去。
线上监控数据:
| 无 softcap | 加 softcap | |
|---|---|---|
| Max 激活值 | 108,416(溢出 FP16) | 70 |
108k 远超 FP16 的 65504 上限,意味着无 softcap 时 FP16 推理直接崩溃;加上 softcap 后最大激活降到 70,给 FP16 留出极大的安全余量。这一改动在生产环境的稳定性意义非常大——它让我们能放心用 FP16 推理而不用担心偶发的数值爆炸。
2.6 优化器:从 RMSPropV2 迁移到 AdamW
这是一个大胆但正确的决定。模型结构去掉了 bias、使用 RMSNorm + weight decay 稳定训练(即 0-齐次网络),此类网络下 AdamW 相比 RMSPropV2 更友好,能更好发挥模型潜力。
为什么 0-齐次网络偏好 AdamW? AdamW 的权重衰减是真正的 L2 正则(与梯度解耦),而原始 Adam 的权重衰减是和 momentum 耦合的。在 0-齐次网络中,weight 的尺度可以自由缩放而不影响输出(norm 会重新归一化),所以 weight decay 唯一的作用就是控制 effective learning rate。AdamW 的解耦机制让这种控制更精确、更可预测。
推荐系统的训练数据与 LLM 有两点显著差异:训练数据分布差异大(来自不同场景、不同时间段、不同地区,分布漂移严重)、样本噪音高(用户行为本身就有大量随机性,曝光偏差、位置偏差也加剧噪声)。因此不能直接用 LLM 的标准参数(lr=1e-5, β₂=0.99),而是需要从 RMSPropV2 的配置出发,通过公式推导找到适合推荐场景的超参配置:
| Stage | lr | β₁ | β₂ | ε | weight_decay |
|---|---|---|---|---|---|
| Pretrain | 8e-4 | 0.9 | 0.99 | 1e-7 | 1e-5 |
| Posttrain | 8e-4 | 0.9 | 0.99 | 1e-7 | 1e-5 |
| Recall SFT | 6e-4 | 0.9 | 0.99999 | 1e-7 | 5e-6 |
SFT 阶段 β₂ = 0.99999:这个看起来夸张的设置,实际上是为了让二阶动量在嘈杂的下游任务样本上表现得更稳定——β₂ 越接近 1,二阶动量的"记忆窗口"越长,能更好地平滑掉短期噪声。SFT 阶段的样本是 pointwise 的,单条样本的方差远高于 Pretrain 序列样本,所以需要更长的二阶动量平滑窗口。
切换到 AdamW 后,HR@1 提升 +8%,且权重范数(WeightNorm)从 500+ 收敛到 70 左右,训练过程更稳定。WeightNorm 的下降不仅是数值上的好看,它还意味着模型在学到等效表达力的同时使用了更小的 weight scale——这种"小权重高表达"的状态泛化能力更强、对噪声更鲁棒。
3. 预训练(Pretrain)
3.1 Tokenizer 设计:三类 Token 的统一序列
预训练的核心挑战是如何把用户的异构行为序列转换为模型可以理解的 token 流。在自然语言中这个问题相对简单——文本天然是 token 序列。但在推荐场景,用户的一次"点击行为"包含商品 ID、商品类目、行为类型、时间戳、来源场景等多个异构信号——把它们都塞进序列又不能丢信息,是一个非平凡的设计问题。
方案设计了三段式 Tokenizer:
Context Info Token
承载场景、时间等推理时已知信息,包括请求场景(source_page_type)、进入来源(enter_from/enter_method)、行为时间差(ts_delta)等。此外还把部分条件信号(如 action_type)编码进 Context Token,作为建模 item 行为类型的 condition 一并输入序列。通过调节 Condition Token 可以让召回满足多种多样的算法和业务需求(如点击目标构造 action_type=click、成单目标构造 action_type=order)。
Context Token 的设计哲学是"把推理时已知的所有信息都当作 prompt 输入"——这与 LLM 的 prompt engineering 思路一脉相承。当线上召回时,request 上下文(用户当前在哪个页面、从哪里跳过来的、当前时间段等)都是已知的,把它们作为前缀 token 输入,模型就可以根据上下文产出场景对齐的召回结果——同一个用户在"逛商城首页"和"逛搜索结果页"会得到完全不同的召回,因为 Context Token 不同。
Semantic ID Tokens
三位 8192 词表 ID,承载核心行为 item 的 SID(Semantic ID)。每个 item 展开为 3 个 SID token,构成粗到细的语义描述,兼顾词表可控与生成步数可控。SID 之间天然带有泛化性:语义相近的 item 共享前缀 code,为模型学习跨 item 的可迁移模式提供了归纳偏置。
为什么是 3 层 8192 而不是 1 层 5 亿(即直接用 PID)?原因是:(1) 1 层 5 亿的 vocab 会让 output projection 的参数量爆炸($d \times 5 \times 10^8$ 即便 $d=128$ 也需要 64GB 仅 output 一层);(2) 1 层 5 亿的 vocab 会让生成式 sample 的搜索空间过大,Beam Search 几乎无效;(3) 3 层 8192 的层级化解码让每步只在 8192 的小空间内 sample,又通过条件依赖 $P(s_2 | s_0, s_1)$ 自动收敛到合理的精细 ID——既高效又精准。
Item Info Token
承载 item 侧的细粒度特征,包括商品 ID(pfid)、叶子类目(leaf_ctg)、卖家(seller_id)等精细标识信号。与 Semantic ID Token 互补:SID 反映内容层语义(多模态特征 + 协同信号经 RQ-KMeans 量化的离散 code),Item Info 则保留传统推荐中被证明有效的精细 ID 特征,粒度更细。
Item Info Token 与 SID Token 的关系类似 NLP 里 word piece 与 word 的关系——SID 承担"语义聚类"的功能(语义近的商品共享前缀 SID),Item Info 承担"精确识别"的功能(同一 SID 下的商品仍可通过 PID 区分)。两者结合让模型既能做粗粒度的语义泛化,又能做细粒度的精确召回。
消融实验验证了各类 Token 的贡献:
| 配置 | HR@1 | SID L0 HR@1 | SID L1 HR@1 | SID L2 HR@1 |
|---|---|---|---|---|
| Item info + context info | - | - | - | - |
| w/o item info | -9% | -4.0% | -3.2% | -1.8% |
| w/o item info & context info | -42.8% | -12.2% | -14.1% | -3% |
Context info 对 HR@1 的贡献高达 -42.8%,是最关键的 token 类型。这个实验结果其实揭示了一个深刻的事实:用户在线行为的可预测性极度依赖上下文。同一个用户在"购物车"和"详情页"的下一个行为分布完全不同——脱离了上下文 token,模型只能利用 SID 级别的弱监督信号,当然学不出强结果。
3.2 数据组织:序列去重与 All-Flat
用户行为去重
原始用户行为会被埋点重复上报多次(曝光到成交的多级行为、场景切换造成的重复上报),直接喂进模型既冗余又会稀释监督信号。一个典型例子:用户在商品 A 的详情页看了 5 次,加购物车 1 次,下单 1 次——埋点系统会上报 7 条记录(5 次 view + 1 次 cart + 1 次 order),但从"用户兴趣建模"角度看,这只是一次有效的"对 A 强烈感兴趣"的事件。如果让模型同时对这 7 条记录做监督,模型会把 80% 的注意力浪费在重复信号上。
方案做了两步去重:
- ListwiseDeduplicateBySession:按固定时间阈值 T(线上取 2h)切分 session,在当前 session 内维护 key
(pid, action_type)的集合,首次出现的事件追加到输出列表,已出现的直接丢弃。这一步去掉的是"同 session 内的重复曝光"——比如用户来回滑动同一个商品被埋点 N 次,只保留第一次。 - SeqConsecPIDDedup:在 Step 1 的输出上再做相邻位置去重,连续落在同一 pid 上的 token,只保留行为漏斗最深、时间最后的一个(按 view < click < cart < order 排序)。这一步去掉的是"同一 item 的多级行为渐进"——把"看了→点了→加购→下单"压缩成"下单"这一最终态,让每个 token 对应一次"有意义的最终行为"。
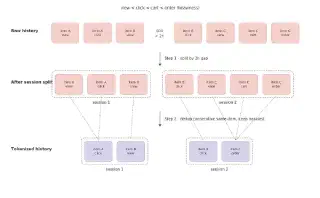
去重后的序列长度从原来的 ~3000 token 压缩到 ~600 token,监督信号密度提升 5 倍,且每个 token 都对应一次"独立有意义"的用户决策——这对训练效率和最终效果都是巨大的改进。
All-Flat 数据组织
预训练阶段采用 All-Flat 组织:用户的历史行为(Context/SID/辅助 token)按时间顺序展平成一条长序列,所有 token 独立入图、独立参与 attention。这样做的目的是让模型看到最完整的交互序列,充分学习长程依赖和多域泛化能力。
All-Flat 与之后 Posttrain 阶段的 Prefill Merge 形成对比——Pretrain 关注"通用性",所以让所有 token 平等参与;Posttrain 关注"任务对齐",所以可以压缩前缀只保留 last-k 信号。这种"先通用、后专用"的设计是对 LLM Pretrain → SFT 范式的精确复刻。
序列组织加速技巧:将上一个 item fine info 和当前 item context token 做 sumpooling,在不损失任何信息的前提下,让序列长度减少 1/5。这个看似不起眼的工程优化在大规模训练上节省了 20% 的计算成本——对于一个 ~800 GPU·days 的 Pretrain 任务来说,等于省下了 160 GPU·days 的实算资源。

3.3 训练任务:SID-only Next Item Predict
训练目标是标准的自回归 Next Item Predict:给定前缀序列预测下一个 item 的 SID token,采用 teacher forcing 训练。Loss 只在 SID token 位置计算(SID-only Loss),Context info 与 item fine info token 不参与 next token loss,避免模型把算力浪费在回归静态特征上:
$$\mathcal{L}_{\text{NTP}} = -\sum_{t=1}^{n} \sum_{k=1}^{3} \log p_\theta\!\left(s_t^{(k)} \mid x_{Teacher Forcing 的工程优势:训练时一条样本同时贡献 L 个 NTP 监督点(每个位置都做一次 next-token prediction),样本效率最大化。这与 Pointwise 训练的 1:1 监督比形成鲜明对比——同样的 GPU 计算量,序列样本能产出 L 倍的有效梯度。
3.4 推荐预训练 Scaling Law
这里有一个非常有意思的发现:推荐系统预训练的 Scaling 不是单变量问题。把 pretrain loss 按熵性质拆解,对应三条相互独立的优化方向:
$$\mathcal{L}_{\text{pretrain}} = \underbrace{\mathcal{L}_{\text{high-entropy}}}_{\text{用户兴趣建模}} + \underbrace{\mathcal{L}_{\text{low-entropy}}}_{\text{condition 映射 + SID 层级}} + \underbrace{\mathcal{L}_{\text{irreducible}}}_{\text{当前可观测的随机性下界}}$$这个分解很直观:(1) 高熵任务对应"猜用户下一秒想要什么",本身就有很高的不确定性,模型学到的是兴趣分布;(2) 低熵任务对应"给定 SID 前缀,下一级 SID 是哪个"——这部分本质是确定性映射,参数足够就能记住;(3) 不可约熵是当前观测下任何模型都达不到的下界,比如用户的随机点击、突发兴趣切换等。
参数量:主要影响低熵任务(SID 映射、condition 建模)。以 500M SID codebook 为例,$\log_2(5 \times 10^8) \approx 28.9$ bits/SID,裸记忆下界约 7.2B 参数。参数不足是线上 SID 不合法率的主因——当模型记不住"3 层 SID 的合法组合"时,Beam Search 生成的 SID 在倒排表里找不到对应 PID,召回直接失败。实验表明 14M → 32M → 114M 参数量,hitrate@1 从 4.0% → 4.8% → 6.0%,提升大部分来自 SID Level 1/2——这正是低熵记忆任务的甜区。
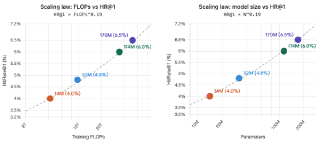
Context 信息量:用户兴趣的不可约熵(Bayes Risk)很高,只建模 SID 的话效果很快到平台期。增加 context token,模型能随着数据量增加持续学到更多,最终效果提升约 66%。这一点深刻揭示:用户兴趣建模的重点要素是 context,其价值由条件互信息 $I(Y; X_{\text{new}} \mid X_{\text{old}})$ 决定,冗余特征只增成本不降熵。
这个观察对工业推荐系统有重要指导意义——当我们想"再加一个特征"时,要问的不是"这个特征有什么信息"而是"这个特征在已有特征条件下还有多少信息"。比如已经有了 user_id 和 history seq,再加 user 性别带来的边际增益就很小(因为 history seq 已经隐含了用户性别信号);但加上"当前请求的页面"这种条件性信息,边际增益就很大(因为 history seq 不包含当前请求的实时状态)。
多任务:在 SID head 后叠加 action 预估 Loss(click/cart/order),SID 的 hitrate 也能涨。LLM 本质是超大型多任务系统,共享底层结构的任务联合训练存在隐式正向迁移。这与 NLP 里 T5 的 multi-task pretraining、UniLM 的多目标掩码等思路一脉相承——多任务不是为了让模型同时擅长多个任务,而是为了让 backbone 学到更通用的表征。
Scaling 的三个杠杆总结:多任务让现有参数学到更多;context 降低 Bayes ceiling 让参数有继续工作的空间;最后参数量给前两者提供承载容量。三个杠杆同时提高,才是生成式推荐预训练真正的 Scaling Law。
需要警惕的反直觉发现:单纯堆参数量而不增加 context 或多任务,效果增益会很快饱和。这与 NLP 的 Chinchilla scaling law(参数量与数据量成 1:20 的最优比例)不完全一样——推荐场景的"数据"维度不仅是 token 数量,还包括 token 的信息密度(context richness)。这要求工业推荐 scaling 必须做"全维度 scaling",而不是单纯地把参数堆上去。
4. Recall Posttrain:对齐召回任务
4.1 Prefill Merge:压缩历史前缀
Recall Posttrain 阶段切换到 Prefill Merge 数据组织:只保留序列末尾的 last-k 个 token 炸开参与 loss 计算,前面的长历史先过 Transformer 再经 sumpooling 压到 MergedToken 上作为上下文占位(5× 压缩)。
具体地,假设原始序列长度 $L = 512$,last-k 取 32,那么:
- 前 480 个 token 经过 Transformer 的部分 forward 计算后被 pool 成 96 个 Merged Token(5× 压缩比)
- 后 32 个 token 完整参与剩余 forward + loss 计算
- 最终入 attention 的有效序列长度从 512 降到 96 + 32 = 128
两个动机:
训练样本组织与线上召回 serving 对齐——前缀历史只需 prefill 一次即可复用到所有 last-k 位置,压缩了输入,线上可以处理更长的序列。在生产环境,召回 latency 的瓶颈往往在 prefill 阶段(O(L^2) 复杂度的 attention),把历史 token 压缩 5× 等于把 prefill 时间压缩到 1/25——这对线上 P99 latency 至关重要。
控制 SFT 阶段的 loss 位点分布,把预测信号集中在最近的 last-k 上,更贴近召回任务"预测未来即将交互的 item"的目标。Pretrain 阶段为了通用性把所有位置都参与 loss,但召回任务关心的本来就是"用户接下来要看什么",所以只在 last-k 上计算 loss 反而能让模型更专注于核心任务。
4.2 Multi-Item Predict:对齐 top-K 召回
训练目标从单步 Next Item Predict 扩展到 Next Multi-Items Predict:模型在 last-k 位置上同时预测未来多个 item 的 SID 分布:
$$\mathcal{L}_{\text{MTP}} = -\sum_{t=1}^{n} \sum_{i=1}^{K} \sum_{k=1}^{3} \log p_\theta\!\left(s_{t,i}^{(k)} \mid x_{为什么 Multi-Item 比 Single-Item 更适合召回? 召回的本质是"从亿级商品中筛出几百个候选",下游粗排/精排再做精细排序。这意味着召回不需要给出"下一个最准的 item",而是要给出"未来一段时间用户可能感兴趣的 item 集合"——后者天然是 Multi-Item 任务。如果只用 Single-Item 训练,模型会过度优化"最准的下一个",但忽略"集合多样性"——线上召回结果会偏窄、覆盖率不足。
Pretrain 越强,SFT 终态越高且收敛越快——400B base 在 step 1000 就达到峰值,100B base 在 step 4000 才达到峰值。因此 pretrain scaling 的收益与 SFT 收益是叠加的,pretrain 并未"吃掉"SFT 的优化空间。
这个发现非常重要——它意味着 Pretrain 与 SFT 的资源投入不是 zero-sum 而是正和。Pretrain 投入越多,SFT 阶段需要的样本量越少、收敛越快、最终效果越好。这与 NLP 领域的"Pretrain helps SFT"经验一致,但在推荐领域得到了首次定量验证。
4.3 Zero-shot 部署评估
一个值得关注的实验:将未见过下游样本的 Foundation Model 直接部署为召回,通过真实用户反馈直接测评模型效果。
Condition Token 的 Prompt 效果:通过 mock 不同的 action type 特征,可以作为 Prompt 让模型产生不同的偏好模式——这意味着一个预训练好的 Foundation Model 天然具备多目标可控的能力。具体来说:
- Mock
action_type = click时,模型生成偏向"高曝光、高点击率"的商品池 - Mock
action_type = order时,模型生成偏向"高转化、高 GMV"的商品池 - Mock
action_type = cart时,模型生成偏向"决策中、价格敏感"的商品池
这种 Prompt 控制能力让 Foundation Model 真正具备了"一模型多用"的灵活性——同一套权重通过不同的 condition prompt 可以服务点击优化、成交优化、加购优化等多种业务目标,无需重新训练。

Zero-shot FM 的本域对齐问题:Zero-shot 部署发现该路召回的成单指标远高于基线,但曝光占比和点击率相比基线都低。排查发现从 merge 到粗排到精排通过率都比较高,但混排直接筛掉了 30% 的曝光——混排目前建模本域曝光的模式暂时无法感知全域兴趣分布。
这是一个非常有趣的"系统级现象"——FM 学到的是全域用户兴趣,所以 zero-shot 召回出来的商品在用户的全域兴趣空间里是合理的,但当下游混排只看本域(比如"商城"内)的历史曝光分布时,会错把"用户曾经在直播间感兴趣但商城没看过"的商品当作"低相关"过滤掉。这类似于 LLM 的 zero-shot 在某些领域表现"看似合理但被下游 evaluator 误判"的问题。
解决方案:一是增加场域特征 prompt(让模型知道当前是商城场景,主动产出商城类商品),二是使用本域的 Pointwise 样本流新增一个训练阶段对齐本域分布(这就是后续 SFT 阶段做的事)。

5. Recall SFT 与 Reward
当前 SFT 基于预训练模型 load 后,在 pointwise 样本下做特征对齐,引入长序列,增加召回 NTP loss 和相应的 reward。
数据输入组织:采用"多行为前缀 + Pointwise 解码"输入组织形式:每个样本同时包含用户的点击、加购、成单三条历史序列,分别以"一个历史行为位置"为基本单元,将商品侧特征、上下文特征和对应的 SID 输入映射到同一表示空间后,在每个位置内融合成一个行为 token(per-position fusion)。三条序列按 order → cart → click 的顺序拼接,中间插入可学习的 SEP token,形成统一的历史前缀,加入绝对位置编码让模型感知序列内的时序关系以及序列间的差异。
为什么三条序列分开拼接而不是按时间合并? 因为不同 action 的语义层级不同——成单(order)是最强意图信号、加购(cart)是中等意图、点击(click)是弱意图。如果按时间合并,模型很难区分"这个 click 后面会不会变成 order"——但分开建模后,order 序列就明确告诉模型"这是已经成交的强信号",cart 序列说"这是决策中的中等信号",click 序列说"这是浏览阶段的弱信号"。这种层级化的输入组织让模型能更精准地捕捉用户的兴趣强度。
Token 化与序列拼装的关键细节:
- Projection to d_model and per-position fusion:将每个位置的
item_info、context_info、sid_input分别通过 Projection 映射到统一维度d_model,再相加融合为单个fused token。这种"先投影后融合"的设计避免了 raw concat 带来的维度爆炸问题——如果 item_info 是 128 维、context_info 是 64 维、sid_input 是 384 维,直接 concat 是 576 维,要再投影到 d_model;先各自投影到 d_model 再相加,参数量更小、计算更高效。 - padding 提取到左侧以减少 Pyramid 机制的损失。Pyramid 机制是说不同 batch 的有效长度差异时,把短样本左 padding 让所有样本的"有效末尾"对齐到序列右端——这样 attention 计算时不会有大量浪费在 padding 上。
- 训练范式对齐 LLM:Tokenizer → Decoder-only Transformer → NTP Loss 与主流 LLM 完全一致,为 Scaling Up 提供了天然基础。
Reward 加权的工程实现:在 NTP loss 之上叠加 reward 加权——对于历史中带有 order 行为的样本,loss 加权倍数 1.5x;带有 cart 的 1.2x;纯 click 的 1.0x。这种加权让模型在训练时优先学习"高价值行为"对应的兴趣模式,与最终业务指标 GMV 直接对齐。
6. Semantic ID:用 RQ-KMeans 替代 Product ID
6.1 为什么需要 Semantic ID
传统推荐系统直接用 Product ID(pid)作为 item 的唯一标识,在判别式框架下没有问题——双塔的 item 塔会为每个 pid 单独维护一个 embedding,端到端学习。但在生成式框架下,模型需要逐 token 预测 item,Product ID 的词表规模(亿级商品)直接导致参数爆炸,而且相近的 pid 之间没有任何语义关系,模型无法迁移知识。
具体地,假设商品库 1 亿,hidden_dim=128,仅 output projection 层(vocab × hidden)就需要 $10^8 \times 128 \times 2\text{B} = 25.6\text{GB}$ 显存(FP16),而且这个层完全是稀疏更新——每次只有少量 pid 被激活,其它 pid 的 embedding 几乎得不到更新。这种"超大稀疏 vocab"在 LLM 时代被证明是低效的设计。
SID 解决了三个痛点:
- 参数爆炸:三位 8192 词表(共 $8192^3 \approx 5.5 \times 10^{11}$ 种组合)远比直接用 pid 的百亿词表参数更可控。每位 8192 的 embedding 只需要 $8192 \times 128 = 1\text{M}$ 参数,三层一共 3M 参数,比直接用 pid 节省 4 个数量级
- 语义缺失:基于多模态特征的 RQ-KMeans 量化,语义相近的商品共享前缀 code。比如所有"红色连衣裙"商品的 SID Level 0 都是同一个码字,模型只要学到"用户喜欢这个 Level 0 码字",就能召回所有红色连衣裙——而不需要为每个具体的 pid 单独学一遍
- 冷启动:新商品只要有多模态特征就能分配 SID,不依赖历史交互数据。这是判别式双塔的硬伤——双塔的 item embedding 必须从历史交互中学,新上架商品因为交互稀疏 embedding 学不出来;SID 不依赖交互、依赖内容,新商品上架的第一秒就有合理的 SID
6.2 RQ-KMeans vs. RQ-VAE
为什么选 RQ-KMeans 而不是 RQ-VAE?
RQ-VAE 是端到端学习的量化网络——encoder 把 item embedding 映射到 codebook,每个 codebook entry 是可学习的向量。但 RQ-VAE 有几个工程顽疾:(1) 训练易码本坍塌——优化过程中部分 codebook entry 永远没有 item 分到,相当于 vocab 浪费;(2) 利用率崩塌:实测利用率经常 < 10%,意味着 8192 的 vocab 实际只有 800 个码字在工作;(3) 在 gumbel-softmax、LR、encoder 结构等一系列调优后仍无法追上 RQ-KMeans,精排 CTR AUC 相对随机 baseline 为 -0.07%
RQ-KMeans 是用经典 K-Means 聚类算法生成 codebook:(1) 聚类过程稳定——K-Means 的迭代收敛性远好于神经网络训练;(2) 100% 利用率——聚类天然让每个簇都有样本;(3) item 分布相对均匀——K-Means 的"最小化簇内距离"目标自然产生大小相近的簇;(4) 并行计算快——可以用 Faiss 等库加速;精排 CTR AUC +0.03%,下游召回/预训练指标均优
串行残差码本路线(粗→细逐层量化):
- Level 0:对原始 item embedding 做 K-Means,得到第一级码字
- Level 1:把"原 embedding − Level 0 簇中心"作为残差,再做 K-Means 得到第二级码字
- Level 2:把"残差 − Level 1 簇中心"再做 K-Means 得到第三级码字
这种残差量化路线与生成式推荐的逐级自回归解码天然对齐——模型先生成 Level 0(粗粒度语义类别),然后基于 Level 0 生成 Level 1(更细的子类别),最后生成 Level 2(最精细的差异化特征)。重建误差可控、语义层次清晰。
6.3 生产配置
- 商品表征:多模态大模型(dim=128),输入商品主图 + 标题 + 类目信息。这一步是关键——多模态 embedding 的质量直接决定了 SID 的语义质量。如果只用类目特征,SID 就退化为类目 ID;用上图像和文本后,“红色丝绒连衣裙"和"红色丝绒礼服"会被聚到同一簇(即便它们的类目可能略有差异)
- 码本规格:三层均匀 8191×3(对比金字塔、倒金字塔和 4095×3,均匀 8191×3 的下游指标、簇纯度、I2I 召回率综合最优)
- 接入通道:Hive Table + Universal Embedding,每日更新
为什么是 8191 而不是 8192? 这是为了留出一个特殊 token(比如 <unk> 或 <pad>),让 vocab 总数恰好是 $2^{13} = 8192$ 同时还有特殊位置可用。这是 LLM 领域的 vocab design 标准做法。
为什么均匀优于金字塔/倒金字塔? 金字塔(如 16384/4096/1024)的设计直觉是"粗粒度多样、细粒度紧凑”,但实测发现这反而让 Level 2 信息量不足,整体表达能力弱化。均匀分配在每一层都给足容量,让模型在三层之间均衡地分担表征压力。
6.4 关键优化:同款簇去重
电商爆款会让大量码字浪费在表达同款商品的噪声变化。比如某款热卖手机壳,可能有几千个 SKU(不同颜色、不同卖家、不同价格),多模态 embedding 几乎相同——直接 K-Means 会把这几千个 SKU 都映射到同一簇,浪费一个码字、且让该簇过度拥挤。
按 SPU 同款簇 ID 对重复商品去重,ROW 样本从 2.6B 压缩到 50M–550M 高质量去重样本,孤点簇相比全量版本提升 +14%,下游精排/预训练指标同步改善。
这个优化的本质是"先做语义去重再做聚类"——用业务先验(SPU 同款)去掉冗余,再让 K-Means 在多样化的样本上聚类,最终得到的 SID codebook 才能真正反映商品的语义多样性而不是 SKU 的噪声变化。
7. 在线链路:生成式召回 Serving
生成式召回的在线链路与传统双塔召回有本质区别,主要包含四个步骤:
7.1 离线 SID 生产与倒排构建
- SID 生产:离线通过 RQ-KMeans 生产 SID,完成全量商品的 pid → SID 映射,产出到 Hive 表以及 UE 服务中
- 倒排索引构建:基于 Hive 的 pid → SID 映射,结合推荐精品池候选以 GMV/Order 等业务指标进行加权,构建倒排索引服务
倒排索引的"加权"很关键——同一个 SID 通常对应多个 PID(因为 SID 的粒度是"语义簇",一个簇里有多个具体商品)。当模型生成某个 SID 后,倒排查询会返回该 SID 对应的所有 PID,但需要按业务价值排序——GMV 高的、Order 多的、库存充足的优先。这一加权步骤把"语义召回"转化为"业务召回",在不破坏模型语义的前提下注入业务先验。
7.2 在线 GR 召回 Serving 流程
- 原始特征获取:抽取用户 profile、seq 以及 context 相关特征,以及根据 UE 服务获取 SID 相关特征
- 基于 GPU 推理服务的用户子图 SID 生成:不同于以往的基于 CPU 索引的召回调用,生成式召回直接改用 GPU 推理服务跑子图生成 SID 结果
- 通过 RPC 请求 GPU 推理服务执行 U 侧子图推理
- U 侧子图采用图内 Beam Search 的方式,在 GPU 上一次性完成模型跑图与 Beam Search 解码,直接生成 Top-K SID 及 Logits
- SID → PID 倒排查询与结果合并:基于生成的 SID、Logits,查询 sid → pid 倒排索引,通过加权 merge 对多个 SID 命中的 PID 进行合并
- 多路召回融合:生成式召回(Foundation GR Recall)作为一路新增召回,与现有的 DVF、PDN 等多路召回并行执行,通过多路 merge 进行结果融合
图内 Beam Search 的工程意义:传统 Beam Search 是"GPU forward → CPU 取 top-K → GPU forward → CPU 取 top-K …“反复跨设备拷贝,每次跨设备开销几毫秒。把整个 Beam Search 写到 GPU 算子里,所有 K 步解码都在 GPU 内完成,跨设备开销降到 0。在 SID 三层解码的场景下,这个优化能让 latency 从 30ms 降到 5ms 以内。
8. 训推优化:让 170M 模型跑得快
将 170M 的 LLM 部署到在线推荐召回是一项重大工程挑战,涉及到训练和推理的全链路优化。生成式召回对线上 latency 的容忍度远低于通用 LLM 服务(推荐召回需要 P99 < 50ms,而 ChatGPT 这类对话场景能容忍秒级 latency),所以训推优化是这个项目能否上线的成败关键。
8.1 Flash Attention
长序列场景下传统 Attention 的问题:显存占用大(直接算 QK^T 产生 length² 量级 Attention Map,batch 2048 × head 4 × length 1024 时单层约需 69GB)、访存开销大、算子调用分散。
Flash Attention 的核心思想是分块计算 + 在线 softmax——把 attention 计算切成小块,让中间结果保持在 SRAM 而不写回 HBM,同时用增量式 softmax 避免一次性物化整张 attention map。具体地:
- 把 Q、K、V 切分成块 $Q_i, K_j, V_j$
- 对每个 (i, j) 块对计算局部 $S_{ij} = Q_i K_j^\top$、$P_{ij} = \text{softmax}(S_{ij})$、$O_{ij} = P_{ij} V_j$
- 用在线 softmax 算法把不同 j 的部分结果合并
这样空间复杂度从 $O(L^2)$ 降到 $O(L)$,且大部分计算都在 SRAM 内完成,访存开销大幅降低。
引入 Triton 版本的 Flash Attention,把 Attention 的空间复杂度压到 $O(\text{length})$,显存不再随序列长度平方爆炸:
- 显存占用下降 1/6 以上
- 吞吐提升 60% 以上
- 支持最高 200M 参数 × 2K 上下文的训练规模
Triton 版本的优势是可定制——可以针对推荐场景的特殊需求(比如 GQA 的反向传播、特殊的 mask 形状等)做定制 kernel,而不受官方 PyTorch FlashAttention 实现的限制。
8.2 梯度累积
梯度累积通过将连续 N 个 step 的反向梯度在本地缓冲区累加、仅在第 N 步触发一次 AllReduce 与 optimizer step。
为什么梯度累积有效? 在大规模分布式训练中,AllReduce 的通信开销可能占总 step time 的 30-50%。每次 AllReduce 都需要全集群同步,且通信带宽是稀缺资源。当 micro-batch 大小受限于显存(无法把 global batch 一次塞进单卡)时,梯度累积让我们可以"虚拟地"扩大 batch size——多个 micro-batch 累加后等效于一次大 batch 的训练。
AllReduce 触发频率降至 1/N,通信流可与后续 micro-batch 的计算流 overlap,进一步压缩 step time。本质上是在显存与卡数受限的条件下,逼近大 batch 训练的收敛特性。Adam 类优化器在大 batch 下的收敛性优势在这里被充分释放。
8.3 梯度重计算(Grad Recompute)
训练时丢弃部分中间激活,反向传播需要时再前向重算一次,以额外计算换取显存:
- 空闲显存 2.7G → 29G
- 显存占用 -43%
梯度重计算的工程取舍:以约 1/3 的额外计算成本换取近一半的显存——这个 trade-off 在大模型训练中几乎是必选项。原因是:(1) 现代 GPU 计算单元(Tensor Core)的算力远远过剩,但显存容量有限,重算这种"用算力换显存"的操作本质是把闲置的算力变现;(2) 显存释放出来后可以用来扩大 batch size 或序列长度,这些维度的 scaling 收益往往远超 1/3 的算力成本。
具体实现上,方案选择层级粒度的重计算——每个 Transformer Block 作为一个 checkpoint 单元,前向时丢弃 block 内的激活、反向时重算整个 block。这种粒度比 attention/FFN 子层粒度的重计算更高效(重算单元更大、kernel 启动开销更少)。

8.4 BF16 训练 + FP16 推理
训练基于 BF16,推理采用 FP16(部分组件暂未完全支持 BF16)。半精度推理在 A10/L40s 线上压测中 QPS 相比 FP32 + Emb Layer 基线 +85%~+90%。
为什么训练用 BF16 而推理用 FP16? BF16 的指数位与 FP32 一致(8 位),动态范围与 FP32 相同(约 $10^{38}$),但精度位只有 7 位——这种"宽范围、低精度"的特性非常适合训练(梯度可能有极大值或极小值,不能截断;但精度损失可被随机性抵消)。FP16 的指数位 5 位,动态范围只到 $\pm 65504$,但精度位 10 位——这种"窄范围、高精度"特性更适合推理(推理时数值已经稳定在合理范围,重要的是精度)。同时 FP16 在很多旧硬件(A10、T4 等)上有原生支持,比 BF16 性能更好。
FP16 的动态范围(最大 6.55e4)需要针对性处理:
- Dense 特征(GMV、停留时长等)可能超过 1M,统一截断到 [-1e4, 1e4]。这一步必须做——线上 dense 特征的实际数值范围远超 FP16 上限,不截断推理直接 NaN
- Attention mask 位置原本使用 -1e9,会直接溢出为 -inf,改为 -1e4 避免溢出。这是一个非常容易踩的坑——FP32 训练时用 -1e9 没问题,切到 FP16 后 -1e9 溢出为 -inf,softmax 后变成 NaN
- Softcap 为各 block 输出提供数值安全带
8.5 Split KVCache 与动态 Beam Size
- Split KVCache:prefill 部分的 KVCache 不做 tiling,通过广播机制在图内展开,Beam Size 可以从 32 开到 512。具体地,prefill 阶段所有 beam 共享同一份历史 KV cache(因为它们的 prefix 相同),decode 阶段才开始为每个 beam 维护独立的 KV cache。这种"prefill 共享 + decode 独立"的设计能在 batch=512 beam 下保持线性显存增长
- 动态 Beam Size:Beam Search 三层采用不同的 beam size,平衡精度与效率。具体地,Level 0 用大 beam(比如 256,因为这一层是粗粒度,需要广撒网),Level 1 用中 beam(128),Level 2 用小 beam(64,因为这一层是精细化,没必要扩散太多)。这种递减式 beam 在保持召回质量的同时把计算量降低近一半
8.6 两阶段 TopK
先在每个 beam 内做一次 topk 截断,充分利用并行,防止原生 topk 退化为 Radix Sort。
为什么原生 topk 在大 vocab 下退化? 当 vocab 8192、beam 512 时,需要在 8192×512 = 4M 元素上找 top-K。GPU 上的 topk 算子在 4M 元素的输入上会切换到 Radix Sort(比堆排序更适合 GPU 并行),但 Radix Sort 的多 pass 启动开销很大。两阶段 TopK 先在每个 beam 内(8192 元素)做局部 top-K,得到 K×512 的中间结果,再做全局 top-K——这样每个 beam 的局部 top-K 都在 8192 元素上做(小到能用堆排序),全局只在 K×512 上做(也很小),整体效率高得多。
效果显著:
latency 下的压测 QPS 从 59.8 涨到 1180(约 20× 提升)
20 倍的 QPS 提升是这个项目能上线的关键工程贡献——没有这个优化,170M 的 GR 召回 latency 会远超线上预算,根本无法上线。
8.7 攒 batch 推理
攒 batch 进行推理,提高 SMA(流式多核加速器利用率):吞吐单机 300 → 850。
线上请求的天然 batch_size = 1(单个用户请求),不做攒 batch 的话 GPU 利用率极低(很多 SM 闲置)。在 RPC 入口做"等待短窗口、攒成大 batch、统一推理、按用户拆分返回"的机制,能把 GPU 利用率从 30% 拉到 80% 以上。攒 batch 的窗口大小是 trade-off——窗口越大 throughput 越高、但单请求 latency 越长。本方案选择 5ms 窗口,在 throughput 与 latency 间取平衡。
9. 实验结果
9.1 线上 A/B 实验
实验时长:8 个完整天;流量:16% 每组,共 32%;地区:SEA;模块覆盖 Mall | OC | CART | Trade Path | Diversion | Category Tab。
核心业务指标:
- 电商 GMV:人均 GMV +0.157%(p=0.06)
- General Mall:GMV/user +0.3742%,product_click_per_user +0.3133%,main_order_per_user +0.4417%,PV_CTR +0.2403%,UV_CTR +0.1298%
- Mall Feeds:人均点击卡片次数 +0.6258%,PV_CTR +0.6120%,uv 立购率 +0.2772%
- Diversity 提升:点击一级类目数 +0.5466%,支付一级类目数 +0.7175%
- Cold Start 改善:0 单商品 PV +0.2877%,0 单商品点击 +1.2629%
- 广告兼容:Shop Ads Overall Advertiser Value +0.2681%,Overall Cost +0.1509%
指标解读:
- GMV +0.374% 在数亿用户的电商体系下意味着每天数百万到上千万 GMV 增量——这是巨大的业务收益
- Diversity 提升说明 SID 的语义泛化能力有效——用户被推荐到了之前从未交互过但语义相关的商品
- Cold Start 改善是 SID 框架的核心价值之一——0 单商品(即没有任何历史成交的商品)的曝光和点击都显著提升,说明 SID 让冷启动商品也能被合理召回
- 广告收入正向意味着新召回不仅没挤占广告位,反而让广告也跟着受益(更精准的召回 → 更精准的广告匹配)
9.2 ROI 与效率收益
- ROI +0.04%,增量 ROI 237
- 训练时间:通过参数加载加速迭代,从 49.8 天 → 12.3 天(节省 75%)
- 通过引入 FLA、FP16 等训推优化:ROI +0.11%,增量 ROI 277
训练时间从 49.8 天降到 12.3 天这一指标值得特别强调——这意味着模型迭代速度提升 4×,每个月可以跑 2-3 轮实验而不是只能跑 1 轮。在快速变化的电商业务中,迭代速度本身就是核心竞争力。
9.3 模型参数演进
本次上线为 0.17B 的初步版本,预期进一步 Scaling 到 0.6B → 6B 阶段,能够进一步释放更多收益。这个预期来自 Scaling Law 实验的清晰外推曲线——从 14M → 32M → 114M 的三档实验显示 hitrate 持续提升且未饱和,外推到 600M、6B 量级仍有显著空间。
但 Scaling 不是简单的"参数堆上去”——按第 3.4 节的 Scaling Law 分析,参数量必须与 context richness 和多任务设计配套提升。下一阶段的工作重点是:
- 更长序列:从 512 提升到 2048+,让模型看到更长的用户历史
- 更丰富的 context:引入 PDP 主商品、店铺信息等,进一步降低 Bayes ceiling
- 更多预测任务:在 SID head 之外增加 action 预估、价格预估等多任务,让 backbone 学到更通用的表征
- 更大参数:在 1-3 都做到位的前提下,把参数量从 170M 推到 600M 甚至 6B
10. 工程思考与总结
10.1 三个关键 Milestone
首次走通 Foundation Model 参数加载范式:算力最重的 Pretrain 阶段使用序列样本训练,样本利用效率较传统 pointwise 样本提升 L 倍。多阶段、多形态的输入组织充分利用 Transformer 对输入的灵活性,在不动 backbone 的前提下通过输入侧迭代持续压榨参数性能,为后续多阶段共享 FM 与 KV Cache 奠定基础。
召回阶段切换为生成式范式:端到端逐 Token 建模,有利于捕捉细粒度兴趣与语义关联;Semantic ID 显著改善模型泛化能力,同时生成式的计算框架推理复杂度解耦商品库规模,Scaling 空间更大。
One Transformer 理念的完整落地:同一套 backbone 结构在 Pretrain → Posttrain → SFT 的多个阶段中保持不变,阶段间切换仅需调整样本组织形式、loss 与优化器配置等,打通了从 Foundation Model 到各下游任务的参数迁移链路。
10.2 Scaling 的正确姿势
这次工作揭示了推荐系统预训练 Scaling 的三个独立杠杆:
- 多任务:让现有参数学到更多(提高样本效率)
- Context 信息量:降低 Bayes ceiling,让参数有继续工作的空间
- 参数量:给前两者提供承载容量
三个杠杆缺一不可。简单堆参数而不降低不可约熵,最终会被 Bayes ceiling 卡住;只降低熵而参数量不足,则无法承载足够的表示能力。这是一个需要系统工程与算法协同的 Scaling 路线,而不是简单的"把参数量堆上去"。
这个观察对后续工业推荐 LLM 化有重要指导意义——在规划 6B、60B 量级的推荐 FM 时,必须同时规划"context 维度的扩展"和"多任务设计",否则参数 scaling 的边际收益会很快饱和。
10.3 值得关注的工程细节
几个在实施过程中发现的非显而易见的要点:
AdamW 超参不能直接套用 LLM 的配置:推荐系统数据分布差异大、样本噪音高,需要从原有优化器的配置出发推导适合的超参,而不是直接用
lr=1e-5, β₂=0.99。SFT 阶段 β₂=0.99999 这种"极端长尾平滑"的设置在 LLM 里很少见,但在嘈杂的推荐 pointwise 样本上效果显著。Residual Rescale 是 scaling 的保险:层数大于 6 就很容易训崩,Residual Rescale 是关键。单独做 QK Norm 不够,还需要控制残差路径的方差累积。这两个机制是协同关系——QK Norm 控制 attention 内部的数值稳定,Residual Rescale 控制层间残差的方差累积,缺一不可。
SID 码本规格的选择有门道:均匀 8191×3 优于金字塔结构,且码本利用率需要保持 100%——RQ-VAE 的码本坍塌问题是一个真实存在的工程陷阱。简单的 K-Means 反而比复杂的 VAE 更适合工业场景,这印证了"工程上选择简单稳定方案优于复杂前沿方案"的经验。
Zero-shot FM 的本域对齐问题:Foundation Model 预训练学到的是全域兴趣分布,直接部署到特定场景时可能因场域分布偏差被混排拦截。需要增加场域 Condition Token 或额外 SFT 阶段对齐。这是 LLM 时代推荐系统的新型挑战——FM 学到的"通用知识"如何与下游"特定任务"对齐,是一个值得长期研究的问题。
两阶段 TopK 是生成式召回推理的关键优化:20× 的 QPS 提升来自一个看似简单的工程改进,说明在 Beam Search 这类迭代式解码中,数据结构的选择对推理延迟有决定性影响。在工业推荐系统的 LLM 化进程中,这类"看起来不起眼但影响巨大"的工程优化往往是上线成败的关键。
FP16 推理的数值陷阱:从 BF16 训练切到 FP16 推理需要全链路检查数值范围——Dense 特征截断、attention mask 改值、Softcap 配合——任何一处遗漏都会让推理直接 NaN。这种"训推精度切换"的工程复杂度往往被低估。
梯度累积 + 梯度重计算的协同:两个看似独立的工程优化在大模型训练上有协同效应——梯度重计算释放显存让单卡能跑更大 micro-batch,梯度累积让多个 micro-batch 等效于大 global batch,最终在显存受限的 GPU 上逼近大 batch 训练的收敛特性。
10.4 未来展望
- Scale-up:从 0.17B → 0.6B → 6B,根据 Scaling Law 曲线预计能持续释放收益。下一档的 0.6B 模型预期再带来 ~0.3-0.5% 的 GMV 提升,6B 量级则需要工程上的进一步突破(多机训练效率、推理 latency 优化等)
- KV Cache 共享:Foundation Model 作为多任务的共享底座,粗排/精排加载同一套 FM 参数后,历史的 KV Cache 可以在不同阶段复用,进一步降低推理成本。这一思路类似 LLM 服务的 prefix caching——当多个下游任务共享前缀时,prefix KV cache 可以被复用,端到端节省大量计算
- Condition Token 扩展:价格带、冷启动偏好、ROI 要求等都可以作为 Condition Token,实现更细粒度的可控召回。这相当于把"业务运营策略"从模型外的硬规则迁移到模型内的 prompt 控制,让算法具备更强的灵活性
- 多模态输入:将 PDP 主商品、店铺 SellerID 等语义更丰富的 Context 纳入序列,进一步降低用户兴趣建模的不可约熵。多模态信号是当前 context 维度的最大潜在杠杆——商品图片、用户头像、视频内容都可以编码成 token 输入序列
- RLHF 范式引入:当前 SFT 阶段用了简单的 reward 加权,未来可以引入完整的 RLHF 流程(PPO / DPO),让模型直接对齐 GMV、留存等业务指标,而不是中间代理目标。这一步是从"监督学习推荐"到"强化学习推荐"的范式切换,潜在收益巨大但工程复杂度也高
10.5 LLM 范式给推荐系统带来的启示
回到本文开头的问题——为什么 LLM 范式适合推荐系统?经过这次工程实践,可以给出更深入的回答:
第一,LLM 的训练范式提供了 scaling 的清晰路径。判别式推荐系统的 scaling 曲线很快饱和,而 LLM 范式的 scaling 曲线还远未到顶。这意味着在算力持续增长的未来,LLM 范式的推荐系统会持续享受到硬件红利,而判别式系统会落后。
第二,LLM 的"输入即 prompt"思路解耦了模型与任务。同一个 FM 通过不同的 prompt 可以服务不同的业务目标——这种灵活性在传统推荐系统中是不存在的(每个目标都需要一个专门的模型)。
第三,LLM 的语义泛化能力解决了冷启动。Semantic ID 让新商品也能被合理召回——这在判别式双塔时代是几乎无解的问题。
第四,LLM 的工程优化生态可以直接复用。FlashAttention、KV cache、Beam Search 等 LLM 领域的成熟工程优化,几乎可以无损迁移到生成式推荐场景。这意味着推荐系统不再需要从零造轮子,可以站在 LLM 社区的肩膀上快速迭代。
第五,LLM 的"一次预训练、多场景复用"模式重构了团队协作。过去召回、粗排、精排团队各自训自己的模型,现在可以共享同一个 FM——这不仅节省算力,也让团队的工作能力可以"复利"——每一次 FM 的提升都同时惠及所有下游任务。
这些启示远超出本文记录的具体技术细节——它们是推荐系统从"算法工程"向"AI 系统"演进的方向性指引。本次工作只是这条路径上的第一步,未来还有更广阔的空间值得探索。
参考文献
- Bitter Lesson — Rich Sutton, 2019. http://www.incompleteideas.net/IncIdeas/BitterLesson.html
- Shazeer, N. (2020). GLU Variants Improve Transformer. arXiv:2002.05202
- Su, J., et al. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding.
- Ainslie, J., et al. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv:2305.13245
- Dao, T., et al. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS 2022.
- Loshchilov, I., & Hutter, F. (2019). Decoupled Weight Decay Regularization. ICLR 2019.
- Zhang, B., & Sennrich, R. (2019). Root Mean Square Layer Normalization.
- Wang, H., et al. (2022). DeepNorm: Scaling Vision Transformers to 1,000 Layers.
- Lee, J., et al. (2019). Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks. ICML 2019.
- Rajput, S., et al. (2023). Recommender Systems with Generative Retrieval. NeurIPS 2023.
- Touvron, H., et al. (2023). LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971
- Hoffmann, J., et al. (2022). Training Compute-Optimal Large Language Models. arXiv:2203.15556 (Chinchilla)
- Ouyang, L., et al. (2022). Training language models to follow instructions with human feedback. NeurIPS 2022 (InstructGPT/RLHF)
- Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS 2017.
- Kaplan, J., et al. (2020). Scaling Laws for Neural Language Models. arXiv:2001.08361

字节推荐广告算法工程师,专注电商推荐系统。电商广告模型 → 电商推荐模型,兴趣方向:模型结构 Scale Up、序列建模、首点归因、GMV 回归建模。
日常分享搜广推论文 & LLM 笔记,以及自己做的一些小工具和尝试过程。
🔥 欢迎加入 TT 电商推荐团队,期待共建业界领先的推荐系统,完成 LLM 的清晰落地!内推通道 →