KV 高效的 2K 长序列电商精排:OneTrans V3.1 工程实践
本文整理自某大型电商推荐系统内部技术文档,记录了精排模型从 1K 序列扩展至 2K、同时完成模型结构 Scaling Up 与训推效率双重优化的完整工程实践。核心改动四线并进:数据与特征(2K GR 超长序列 + Action Quota + ts_delta/price 分桶)、训练效率(RM Padding + Listwise Squeeze + GQA + QK Norm)、Serving 效率(xmatmul → M-Falcon)、模型容量(d_model 384→512,SeqFormer 5→7 层),最终实现线上 GMV/user +1.02%、main_order/user +1.36%,训练吞吐 +60%,Serving QPS +97%。
0. 背景:v3.0 的四条制约线
0.1 长序列建模为什么是工业精排的下一站
工业级电商精排在过去十年经历了几次阶段性的范式跃迁:从 LR / GBDT + 大规模特征工程,到 DeepFM / DCN 等结构化交叉,再到 DIN / DIEN 等显式建模用户兴趣序列。每一次跃迁都伴随着可处理用户行为信号的深度与广度的扩张。但当 DIEN 把目标 attention 引入精排之后,进一步提升的主要矛盾就从"如何抽取兴趣"转向了"能让模型看到多长的兴趣"——也就是说,user behavior sequence 的长度上限直接决定了模型的天花板。
行为序列变长有两层意义:
- 覆盖更多的细分兴趣。短序列(≤200)几乎只能反映用户最近一两次会话,对于跨场景、跨周期的兴趣信号无能为力。中序列(512–1024)可以覆盖近一周的活跃会话。长序列(≥2048)则进入"多周期 + 多场景兴趣"建模的能力区间,能区分一次性需求(比如生日礼物)和长期偏好(比如运动鞋型号)。
- 稀疏正反馈信号的去稀释。order / cart 这样的高价值反馈在自然行为分布里只占极少数(往往不到 5%)。如果序列长度只有 1K,且按时间均匀采样,那么 95% 的容量都被 click / impression 占据了——模型实际上很难在这样的序列里找到足够的转化信号去学习。把序列长度抬到 2K,相当于多出来 1K 的预算可以分配给低频高价值行为。
但这条路径并非"把 max_seq_len 改一下"那么简单。一旦序列从 1K 抬到 2K,所有 attention/FFN 计算量近似 2×,KV cache 显存近似 2×,再叠加同时进行的模型结构 Scaling Up(更宽更深),单卡显存与训推吞吐都会被同步推上新的瓶颈。v3.0 在 1K 序列下的稳态指标,不能简单地外推到 v3.1。
0.2 v3.0 的现状:1K 序列 + 384 dim + 5 层 SeqFormer
上一代模型(v3.0)将用户行为序列扩展至 1K,并在国际站完成了推全。它的整体形态是一个两阶段的 Transformer 结构:stage-1 用 self-attention 从用户行为序列中抽取兴趣表达,stage-2 用 cross-attention 让候选商品(target item)与序列发生交互。在 d_model=384、SeqFormer 5 层的配置下,模型整体参数量 165M,训练吞吐稳定在 48K instance/s。但运行一段时间后,工程师们发现四条清晰的制约线横亘在继续迭代的路上。
0.3 制约一:序列质量参差,信号覆盖受限
v3.0 的序列混杂了快照序列与 GR 超长序列两个来源。两者的时间戳精度、行为去重粒度、字段对齐方式都不完全一致,需要在序列构建阶段做大量 case-by-case 的兼容逻辑。
更关键的是,这种"混合 + 均匀采样"的做法,导致高频的 click / impression 行为挤占配额,长尾的 order 转化信号被严重稀释。统计显示:v3.0 的有效序列中(去掉 padding 后)平均长度约 555,其中 click 占比超过 50%、impression 占近 18%、cart 不到 30%、order 仅 4% 左右。对于活跃度高的用户,行为体量可能在一周内就突破 1K,1K 长度根本装不下,大量历史兴趣被截断;而对于行为稀疏的用户,序列里又被低质量的 impression 灌满了空隙。
此外,v3.0 缺乏对行为时间间隔和价格区间的显式建模。模型只能从 position embedding 里间接学习时序信号,从 item embedding 里间接学习价格区间——这显然不够。
0.4 制约二:显存瓶颈,2K OOM
训练实现层面存在两处叠加的显存浪费:
Padding 浪费:训练 batch 内不同样本的有效序列长度差异很大,但需要 pad 到统一长度(例如 2K)以便组成规则张量参与计算。padding token 全程参与 stage-1 self-attention 与 FFN 的 forward / backward,产生大量无效 FLOPs,同时消耗显存中的激活、梯度、优化器状态。粗略估算,在 click 序列均值 1200 的条件下,padding 浪费的算力比例接近 40%。
Listwise 重复:精排在工业实现中通常是 listwise 推理——同一个用户请求会带上 N 个候选 item(例如 N=300),每个 item 都要过一遍 stage-1 + stage-2 完成打分。但实际上同一请求里所有 item 共享完全一样的用户序列,stage-1 的 KV 计算被复制了 N 遍,造成显存与算力的巨大浪费。
这两处浪费叠加,使得 v3.0 在 1K 序列下已经把 GPU 显存吃得很紧。一旦尝试将序列从 1K 扩展至 2K,训练直接 OOM。如果不引入新的优化机制,纯靠 batch_size 缩水来腾显存,训练吞吐会进一步崩塌,得不偿失。
0.5 制约三:xmatmul Serving 效率天花板
stage-2 的 cross-attention 在 v3.0 使用 xmatmul 实现:每个 candidate item 独立调度一次 matmul kernel,先算 Q × K^T 得到 attention score,再算 softmax(score) × V 得到 attention 输出。这种实现方式在序列长度较短、item 数较少时尚可,但在精排实际场景下问题非常突出:
- kernel launch overhead 累积:每个 item 一次 kernel,N=300 个 item 就要 launch 300 次 cross-attention kernel。每次 kernel launch 都有约几微秒的固定开销,叠加起来在高 QPS 场景下成为不可忽视的延迟来源。
- kernel 粒度过小:单个 item 的 attention 是 1 × seq_len 的小规模运算,远远填不满现代 GPU 的 Tensor Core 阵列。SM 利用率长期在 6% 左右徘徊。
- 中间结果反复落盘:xmatmul 的 attention score 必须先写回 GPU global memory,再被下一个 kernel 读回,缺少 IO 融合,无法享受 FlashAttention 的 IO 友好优化。
在 v3.0 的 1K 序列 + xmatmul 组合下,Serving 的单请求 latency 已经接近线上预算上限,留给后续模型扩展的余量非常有限。
0.6 制约四:模型容量不足
参数量与模型宽深度均受到前三条制约的间接限制:
- 显存水位太高:v3.0 已经在 1K 序列下吃掉大半显存,没有余量去把 d_model 抬高或者层数加深。
- Serving latency 没有余量:xmatmul 已经把 Serving 推向延迟红线,加宽加深会进一步恶化。
- 训练吞吐低:扩参数 → 训练吞吐进一步下降 → 迭代周期变长 → 实验效率掉一档。
四条制约线相互绑定,构成一个负反馈闭环:想加容量必须先解决显存与延迟,但这两个底层问题不打通,结构上的任何改动都会被反噬。
v3.1 的整个迭代逻辑,就是系统性地打通这四条制约线——先打效率,再做 scaling,最后让结构和数据层的改动同步收敛。
1. 2K 序列扩展与特征丰富
1.1 数据源统一:全面切换 GR 超长序列
v3.0 的序列由快照序列和 GR 超长序列拼接而成,来源不统一导致时间戳对齐与去重逻辑复杂。v3.1 统一切换为 GR 超长序列,序列长度从 1K 扩展至 2K,完全下线快照短序列。
GR 超长序列的优势在于:
- 统一时间精度:所有事件以同一种时间戳精度落地,便于 ts_delta 之类的精细时序特征构造,不再需要在不同源之间做秒/毫秒/分钟的二次对齐。
- 统一去重粒度:GR 序列在落地阶段已经按 (user_id, item_id, action_type, ts) 做了清洗,避免短序列因为埋点重复在序列层再做一次去重。
- 覆盖更长时间窗口:v3.0 的快照序列窗口约一周,GR 超长序列窗口可达数周,为长期兴趣建模提供原料。
离线序列覆盖率对比(v3.0 vs v3.1):
| 指标 | v3.0(1K) | v3.1(2K) | 变化 |
|---|---|---|---|
| 平均有效序列长度(去 padding) | 555 | 1186 | +113.7% |
| order 行为平均覆盖数 | 22 | 48 | +118.2% |
| cart 行为平均覆盖数 | 153 | 193 | +26.1% |
| click 行为平均覆盖数 | 281 | 847 | +201.4% |
| impression 行为平均覆盖数 | 99 | 99 | — |
可以看到:order / cart 这两类高价值行为的覆盖几乎翻倍,click 行为覆盖翻了两倍以上,impression 因为有硬上限保持不变(详见 1.2)。这就是 2K 长度直接带来的"信息体积"扩张。
1.2 Action Quota 过滤:让 order 信号不再被淹没
均匀采样的最大问题是:高频行为(click、impression)轻松占满配额,低频但高价值的 order 被稀释。v3.1 引入按 action_type 的优先级配额机制:
序列仍按时间排序,配额机制只控制每类行为的保留上限,不改变序列内部的时序结构。具体规则:
| 行为类型 | 优先级 | Quota 上限 | 说明 |
|---|---|---|---|
| Order | 1 | 300(p95 长度) | 转化信号,最高优先 |
| Cart | 2 | 600(p95 长度) | 深度兴趣 |
| Click | 3 | 1000(p70 长度) | 主要正反馈 |
| Impression | 4 | 100(硬上限) | 负反馈/上下文,不参与回填 |
| 合计 | — | 2000 | — |
回填机制:若高优先级类型实际行为数不足配额,空出的位顺延给下一优先级类型(impression 除外,始终受 100 条硬上限约束,不参与扩容)。Impression 之所以严格限制,是因为离线实验发现:行为稀疏用户的 GR 序列中 impression 占比极高,若不加限制,序列几乎被无点击曝光填满,序列信噪比显著下降,模型对深度转化信号的建模能力退化。
为什么 quota 而不是采样权重:另一种自然的思路是给不同 action_type 设置不同的采样概率。但精排模型对"序列内时序"是敏感的——采样会破坏行为之间的相对顺序,特别是会让相邻行为的 ts_delta 失真。配额机制只删掉超额的、已经按时间倒序排好的最旧条目,序列内的时序结构完整保留。
为什么对 impression 用硬上限:impression 在 GR 超长序列里可以爆量到几千条(比如重度刷推荐流的用户),即便它对模型有上下文价值,也不应该挤占其它高价值行为的位置。把 impression 锁死在 100 条以内,是工程实践中的"信噪比保护阀"。
1.3 上下文特征注入:ts_delta 与 price 分桶
v3.0 的序列特征缺乏对行为时间衰减和价格区间偏好的显式建模。v3.1 新增三个上下文特征(对数分桶,以离散 FID 形式注入序列):
ts_delta:相邻行为时间间隔(用户节奏感知)。捕捉用户行为节奏是否密集,是建模兴趣切换、会话边界的核心信号。ts_delta_to_reqtime:行为距 request 时间的间隔(时序衰减建模)。模型可以据此学习兴趣的衰减曲线——一周前的 click 和昨天的 click 显然权重不同。price:商品价格对数分桶(价格区间偏好)。同一类目下,用户对价格段的偏好往往是稳定的(比如总是买 100~200 元的运动鞋),这个信号在 v3.0 里完全没有被显式注入。
对数分桶的理由:电商场景的时间间隔与价格都是长尾分布——很多 ts_delta 集中在分钟级以内,但也有少量跨周/跨月的间隔。直接做线性分桶会让大部分桶集中在低位,分辨率不足。对数分桶后,分布更均衡,模型更容易学到细粒度的差异。
FID 化注入:所有连续值通过对数分桶映射成离散桶号(FID),再经过 embedding 层进入序列。这种处理方式把"连续值"转成"类别值",让模型可以用 embedding 的方式学习每一段区间的语义,而不是依赖一个 1 维的连续输入。
1.4 Index-only 序列构建加速
序列构建流程中的去重、防穿越、配额截断三个步骤原本每步都产出完整的新序列张量(n_features × seq_len),三步串联意味着三次全量拷贝。
v3.1 将三步统一为 Index-only 模式:只维护一个有效位置的 index 数组,最终用一次 gather 对所有特征列统一执行。
Index-only 的核心好处:
- 减少中间拷贝:原方案每次都要构造 (
n_features,seq_len) 的中间张量,重复成本很高。Index-only 只携带 index 数组(int32),最后才做一次 gather。 - 降低内存峰值:中间状态体积下降到
seq_len级别,对 Rosetta 图调度更友好,避免触发 spill。 - 算子数减少:原来是 N 个步骤 × N 个特征 = N² 量级算子,现在压缩到 N + 1 个算子。Rosetta 的图执行调度更紧凑。
收益:减少 Rosetta 中间算子数、降低内存峰值,对 Rosetta 图的内存调度更友好。
2. 结构 Scaling Up
效率优化释放显存与算力预算后,v3.1 同步推进了模型结构的 Scaling Up,从多个维度扩充模型容量。
2.1 加宽:d_model 384 → 512,TruncatedNormal 初始化
为什么直接加宽容易崩?
在不调整初始化的前提下加宽,输出方差会近似按比例放大(384→512 约 1.33×,384→768 接近 2×),导致中间激活、残差分支整体鼓胀,把激活推入非线性饱和区,线上预估分布和校准瞬间漂移。
数学上看,对于一个全连接层 $y = Wx$,如果 $W$ 的元素方差为 $\sigma^2$,输入 $x$ 维度为 $d_{in}$,则输出方差近似为 $d_{in} \cdot \sigma^2$。当我们把 $d_{in}$ 从 384 抬到 512 而不调整 $\sigma$ 时,输出方差自动放大约 33%。在多层串联的网络里,这种放大是指数级累积的——5 层 SeqFormer 跑下来,输出方差可能放大 4× 以上。激活值进入饱和区后,gradient 消失,训练走偏。
解决方案:TruncatedNormal std=0.02
实验发现,使用 TruncatedNormal 且 std=0.02 相比随机初始化方式效果更明显且训练更稳定。同时对 QKV 矩阵也采用 TruncatedNormal std=0.02 初始化:
| 改动 | CTR AUC | CTR UAUC | instance/s |
|---|---|---|---|
| 基线(384) | — | — | 52 |
| A: 512 + RandomNorm std=0.05 | +0.05% | +0.16% | 37 |
| B: 512 + TruncatedNorm std=0.02 | +0.09% | +0.21% | 37 |
| C: B + QKV TruncNorm std=0.02(LR) | +0.16% | +0.28% | 38 |
| D: C + dim=768 + SwiGLU clip | +0.26% | +0.37% | 24 |
最终选用方案 C(d_model=512, QKV TruncNorm),在效果与吞吐之间取得最优平衡。
为什么 TruncatedNormal 优于 RandomNormal:TruncatedNormal 把 ±2σ 之外的极端权重直接截断重采样。这避免了极少数权重值过大导致初期激活异常爆炸——这些异常激活会让 LayerNorm 的 running statistics 出现长尾,需要很多 step 才能洗掉。在宽模型上这种长尾恢复尤其慢,因此 TruncatedNormal 的"无极端值"特性带来的训练初期稳定性收益就更明显。
为什么 std=0.02 而不是 0.05:std=0.05 是一个相对常见的默认值(很多 PyTorch 默认初始化函数采用),但在 d_model 较大时,0.05 仍然偏大。0.02 是 GPT-2 / BERT 系列论文里给出的经验值,对 d_model ∈ [256, 1024] 的范围都有不错的稳定性表现。
QKV 单独初始化的必要性:Attention 模块的 QKV 投影矩阵决定了 attention score 的分布。如果 QKV 也按全局默认初始化,score 的方差容易随 d_model 放大。给 QKV 单独用更小的 std=0.02,相当于把 attention score 的初始尺度压回到温度合理区间,避免开训前几十个 step 内 softmax 直接进入"top-1 占据所有权重"的退化状态。
2.2 叠层:SeqFormer 5 → 7 层,Solar Copy-and-Stack
Solar 两阶段训练 + Copy-and-Stack:
- 第一阶段:用较浅较短的序列结构学习主干模式(高吞吐),以 5 层 384 dim 为基础学好主干特征
- 第二阶段:从第一阶段 checkpoint 出发,通过 copy-and-stack 把已有层复制堆叠到 7 层(层映射如
0→1→2→3→2→3→4),恢复长序列与深层结构继续训练
这一策略同时获得两类增益:参数量增加带来的容量增益 + 嵌套深度增加带来的推理/组合能力增益。
为什么不直接训 7 层? 直接从头训一个 7 层 + 2K 序列的模型,对显存、训练吞吐、训练步数三方面都有压力。两阶段的好处是:
- 第一阶段用较窄、较浅、较短序列的设置训得很快,能用相对低的成本探索好基础参数。
- 第二阶段 copy-and-stack 直接复用第一阶段已经学到的 representation,省掉重新学习主干模式的步数。
- 第二阶段才把 d_model、层数、序列长度全部抬上来,训练总时间反而比直接训 7 层更短。
Copy-and-Stack 的层映射逻辑:以 5 层 → 7 层为例,使用 0→1→2→3→2→3→4 的映射,把中间的层 2 和层 3 复制一份。复制中间层而不是首层或尾层,是因为:
- 首层负责 raw embedding → 表达空间的转换,复制会让前几层冗余。
- 尾层往往负责输出对齐,复制会破坏尾部结构。
- 中间层是抽象语义层,复制带来的是"加深抽象路径",最贴合"嵌套深度增益"的目标。
Looped Layer 对照实验:为了分解"参数量"与"嵌套深度"两个因素的贡献,同时做了 Looped Layer 实验——复用同一 block 的参数(0 1 2 3 4 → 0 1 2 2 3 3 4,权重完全共享,只涨嵌套深度)。与 Solar 对比,可以探索精排模型叠层收益的本质来源。
如果 Looped Layer 能拿到接近 Solar 的离线收益,那么叠层收益主要来自"重复 forward"带来的非线性组合深度,而不是新增参数量;反之则说明参数容量才是主要驱动因素。
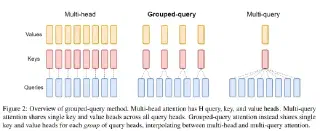
2.3 GQA:8Q/2KV,KV 显存降低 4×
MHA 下每个 query head 独立维护一套 KV,KV 显存随 head 数线性增长,在 d_model=512 这种宽模型上带宽压力进一步放大。切换为 GQA(8 query head 共享 2 KV head),KV 显存降低约 4×。
GQA 的数学定义:标准 MHA 中,每个 head $i$ 都有独立的 $W_Q^{(i)}, W_K^{(i)}, W_V^{(i)}$,head 数为 $H$,每个 head 的 KV 显存为 $L \times d_{head}$,总 KV 显存为 $H \times L \times d_{head}$。
GQA 把 $H$ 个 query head 分成 $G$ 个 group,每个 group 内的 query head 共享一组 KV head:
$$ \text{Q heads} = H, \quad \text{KV heads} = G, \quad \text{group size} = H / G $$KV 显存变成 $G \times L \times d_{head}$,相比 MHA 减少了 $H/G$ 倍。
G 的选择:
- $G = H$:标准 MHA,没有 KV 复用。
- $G = 1$:MQA(Multi-Query Attention),所有 query head 共享一套 KV。激进省内存但精度损失较大。
- $G \in (1, H)$:GQA,介于两者之间。
v3.1 选择 $H = 8, G = 2$(即 group size = 4),显存减少 4×。
为什么是 8Q/2KV 而不是 8Q/1KV:实验中 8Q/1KV(即 MQA)的早期 AUC 损失更大,且后期收敛后也无法完全恢复。GQA 在 group size 较小时(2 或 4),仍然保留了一定的 KV 表达多样性,不会像 MQA 那样把所有 head 强制压在同一个 KV 上。
关键实验发现:早期训练窗口 GQA 有负向波动,充分收敛后反而超过基线。
| 配置 | 早期 AUC(0601-0630) | 充分收敛 AUC(1001-1031) | 吞吐提升 |
|---|---|---|---|
| 512, 8Q/8KV | 基线 | 基线 | 35k/s |
| 512, 8Q/4KV | -0.10 | -0.05 | +8.57% (39k/s) |
| 512, 8Q/2KV | -0.09 | +0.04 | +20% (43k/s) |
这一现象说明:GQA 的负向是训练不充分的假象,在收敛充分的前提下,2 KV-Head 配置能在质量不跌甚至小幅提升的情况下提供显著的吞吐和带宽收益。
底层机理:GQA 通过参数共享降低了 KV 的表达冗余。模型需要更多步数才能在降低的 KV 容量下学到足够的用户序列模式——前几十亿样本的训练里,GQA 比 MHA 看起来"差一点",但这只是参数被压缩后需要更多训练样本去优化的自然现象。一旦训练样本足够(约 100B 量级),GQA 反而因为正则化效应(参数共享起到隐式正则)和带宽友好(KV cache 小,更容易被缓存)而超过 MHA。
带宽收益的工程意义:在 attention 计算里,KV 是被 query 反复读取的"被动数据"。KV 越小,越能被 L2 / SMEM 缓存,越能减少对 HBM 的访存。在精排这种典型的 memory-bound 场景下,KV 减少 4× 直接转化为推理吞吐提升约 20%。
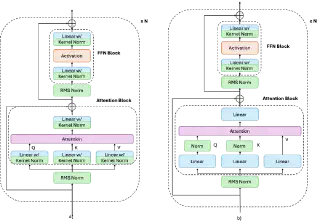
2.4 QK Norm:替换 Kernel Norm,稳定深层 Attention
v3.0 使用 Kernel Norm 稳定训练,但实验发现 Kernel Norm 对模型权重约束过强,影响训练效果,且增加了不必要的计算量。v3.1 参考主流 LLM 的做法,引入 QK Norm 替换 Attention 模块中的 Kernel Norm:
在计算完 $Q = XW_Q$、$K = XW_K$ 后,对 Q 和 K 分别做一次 RMSNorm 归一化,归一化后的 Q、K 再参与 Attention 计算。同时去掉了 QKVO 矩阵对应的 Kernel Norm 及其 bias。
QK Norm 的数学形式:
$$ \hat{Q} = \text{RMSNorm}(Q), \quad \hat{K} = \text{RMSNorm}(K) $$$$ \text{Attention}(\hat{Q}, \hat{K}, V) = \text{softmax}\left(\frac{\hat{Q}\hat{K}^T}{\sqrt{d_{head}}}\right) V $$RMSNorm 把 Q、K 的每一行(每一个 token 的 head 向量)归一化到固定的 RMS scale,softmax 输入的 scale 不再随 token 内容动态变化。
为什么 Attention score 容易发散:朴素 attention 中 $QK^T$ 的方差与输入向量的范数强耦合,序列越长、向量范数越分散,softmax 输入的方差越容易放大。一旦某些 token 的 $\hat{Q}\hat{K}^T$ 异常大,softmax 会退化为 one-hot,梯度从此消失,训练不再继续。深层 Transformer 在长序列下尤其容易触发这个退化。
QK Norm vs LayerNorm/Kernel Norm:
- LayerNorm 是在 attention 之前对完整 input 做一次归一化,但这没有直接约束 $QK^T$ 的尺度——QKV 的投影权重还是可以放大方差。
- Kernel Norm 是对 QKV 矩阵的列向量做范数约束,对权重直接做 hard constraint,但权重的尺度不等于激活的尺度,且这种 hard constraint 限制了模型表达能力。
- QK Norm 直接对 Q、K 做归一化,等价于把 attention 的相似度计算从"点积"变成"cosine 相似度"再放大 $\sqrt{d_{head}}$ 倍,从根本上限制了 score 的方差。
与温度参数的关系:QK Norm 之后 $\hat{Q}\hat{K}^T \in [-d_{head}, d_{head}]$ 的尺度区间稳定,因此 softmax 不需要额外学习温度系数。一些 LLM 实现里 QK Norm 之后会再乘一个可学习温度 $\tau$ 进一步精调。v3.1 沿用 RMSNorm 自带的可学习 gain,等价于嵌入了温度系数。
与 GQA 的协同:GQA 把 KV head 数压缩,每个 KV 要服务多个 Q——这意味着 KV 的有效维度变小,对 score 异常更敏感。QK Norm 在 GQA 下尤为重要,能避免少量异常 score 把整组 attention 引爆。
离线效果:CTR UAUC +0.08%
2.5 Fid 统一 Slice:消除特征与序列的 Embedding 割裂
历史上因为模型是热启的,总是通过加 slice 的方式扩维度,造成同一 slot 上往往有多段 slices,特征和序列对同一特征值分别训练两段不同的 embedding。
这一设计的问题是:Transformer Attention 需要费力学习这两段 embedding 之间的联系,严重阻碍模型对 Target & Seq 之间关系的捕获。
v3.1 对代码进行重构,让特征和序列复用同一段 slice,多段 slice 合并为一段(维度向下取整到 32 的倍数保证计算效率)。
为什么 32 的倍数:现代 GPU 的 Tensor Core 偏好 16 / 32 / 64 这样的对齐维度。任意维度都会触发 padding 或 fallback,反而拖慢计算。32 是兼顾灵活性和效率的常用对齐粒度。
离线收益:CTR AUC +0.1%,CTR UAUC +0.2%
3. 训练效率优化
3.1 RM Padding:Ragged Sequence 消除 Padding FLOPs
问题根因:训练时所有序列被 padding 至固定长度(2K),padding token 全程参与 stage-1 的 attention 及 FFN 计算。以最长的 Click 序列为例,均值约 1200,意味着约 40% 的计算资源消耗在 padding 上。
更糟糕的是,padding 不仅消耗计算,还参与梯度回传——尽管 attention mask 把 padding token 的 attention 输出 mask 掉了,但 backward 时 padding 位置仍然会产生梯度分量,这些梯度虽然最终会被 mask 抵消,但显存中的中间激活、grad buffer 都已经付出。
方案:启用 RM Padding(use_rmpadding=True),将 padded 序列转为 ragged 表示,attention 与 FFN 计算仅在有效 token 上进行,实际开销随 avg_len 线性缩放,输出与 padded 路径数值等价。
Ragged 表示的核心思路:把 batch 内所有样本的有效 token 拼接成一个一维张量(total_valid_tokens),同时维护一个 cu_seqlens 数组(cumulative sequence lengths)记录每个样本的边界。Attention 计算时通过 varlen_flash_attn 直接用 cu_seqlens 划分边界,自动保证每个样本只能 attend 到自身 token,不需要显式 mask。
原始 padded: [s1_t1, s1_t2, PAD, PAD, s2_t1, s2_t2, s2_t3, PAD]
└─────── sample 1 ───────┘└─────── sample 2 ──────┘
ragged 拼接: [s1_t1, s1_t2, s2_t1, s2_t2, s2_t3]
cu_seqlens: [0, 2, 5]
主要技术工作:
① Ragged 算子开发
模型包含 pertoken 处理逻辑(per-token 投影、per-token gating 等),需要在 ragged 状态下对变长序列进行切割与合并。为此开发了一套基于 Ragged Tensor 的 CUDA 算子:
ragged_split:按 split pos 对变长序列进行头部/尾部切割ragged_merge:将处理后的变长序列重新拼接ragged_truncate:按样本动态截断
这些算子的核心难点不在于功能逻辑,而在于:保持 cu_seqlens 在算子前后的一致性。任何一个算子维护错了 cu_seqlens,都会让后续 attention 的样本边界错乱,导致跨样本信息泄露——这是一个非常隐蔽且难以定位的 bug。所有算子都内置了 cu_seqlens consistency check 在 debug build 中。
② 模型 Transformer 逻辑重构
引入 RM Padding 后,XLA 因 Tensor 变长而失效,原有融合 Kernel 被打散。重新设计了 Ragged Tensor 状态管理流程,在进入 Transformer 之前即执行 RM Padding,后续所有层不再执行 padding 操作,实现全链路 RM Padding。
具体重构包括:
- 入口转换:在 stage-1 输入处一次性把 padded 张量转 ragged,后续所有层维持 ragged 状态。
- FlashAttention 使用 varlen 接口:Attention 调用
flash_attn_varlen_func而不是普通flash_attn_func,靠 cu_seqlens 自动识别样本边界。 - FFN 直接在 ragged 上做:FFN 是 token-wise 的,直接在拼接后的张量上跑就行,不需要任何额外处理。
- 出口还原:在最后输出阶段,再用
ragged_to_padded还原成 (batch, seq_len, dim) 给后续 listwise 计算。
③ NaN 梯度修复
集成 Triton 融合算子(fused_swiglu、fused_matmul)后,训练中出现 NaN。排查定位到边界场景:当 batch 中某些样本的 ragged 序列长度为 0 时,融合算子的 bias 梯度计算会将未初始化显存值赋给梯度。通过在 CUDA Kernel 中对空输入场景增加 cudaMemset 显式初始化为 0 解决。
这是 RM Padding 带来的典型新问题——padded 实现下"长度为 0 的样本"是被 mask 掉的,永远不会真正进入算子;而 ragged 实现下,“长度为 0 的样本"对应一段 length=0 的拼接片段,会真实地进入 kernel,触发 kernel 内部对边界条件的处理。这种边界条件在 padded 时代根本不需要考虑,迁移到 ragged 之后必须逐一补齐。
3.2 RMSNorm 融合算子:补齐反向算子缺失
RM Padding 后 XLA 自动融合失效,原本被融合的 RMSNorm、FFN element-wise 算子被展开为多个独立 Kernel,出现性能回退。此外公司内部此前仅有 RMSNorm 的前向算子,缺少反向算子,无法支持训练场景。
v3.1 使用 CUDA 开发了 RMSNorm 融合算子(含前向与反向),采用以下优化技术:
- 向量化访存:利用 Pack 技术(
float4、half2),每线程一次读取多元素,提升显存带宽利用率。在 H800 / A100 上,向量化 load/store 能把访存吞吐提升约 2~4×。 - 编译时多态:通过
DISPATCH_BOOL宏将HasResidual、HasGamma等运行时判断转化为编译时模板参数,消除 Kernel 内的分支指令。每条 if-else 在 CUDA warp 里都是性能刺客——编译时多态把它们彻底消除掉。 - 寄存器缓存 + One-Pass:前向计算将输入暂存至寄存器,在计算完 Variance 后直接从寄存器读取进行归一化,IO 访问量减少 50%。这个优化要求 d_model 不太大(每个线程能放下一个完整 head 的元素)。在 d_model=512 / head=8 / d_head=64 的情况下,每线程 64 元素,正好可以放进寄存器。
- 两阶段梯度归约:针对
grad_gamma,采用 Block 局部归约 → Workspace → Global 归约的两阶段策略,避免 Batch Size 较大时atomicAdd的性能衰退。直接atomicAdd到 global memory 在 batch 较大时会出现严重的争用,吞吐下降到 1/10 都有可能。两阶段归约把绝大多数 add 集中在 SMEM 内完成,最后一次性写回。
3.3 RM Padding + RMSNorm 融合的训练收益
| 指标 | 优化前 | 优化后 | 变化 |
|---|---|---|---|
| Instance Throughput | 15K/s | 24K/s | +60% |
| SM Activity | 79% | 75% | -5%(减少无效 FLOPs,SM 使用更精准) |
| Tensor Core Active | 3.52% | 5.06% | +43.8% |
值得关注的指标解读:
- Instance Throughput +60%:这是直接业务收益,每秒能多过 60% 的训练样本。
- SM Activity -5%:看起来像下降,实际上是好事。SM Activity 降低意味着 GPU 不再空转处理 padding,所谓"忙碌时间少了”,但有效计算更密集。
- Tensor Core Active +43.8%:这个指标才是真正的"质量提升"——单位时间内进入 Tensor Core 的有效计算量大幅提升,说明优化后的 GPU 时间花在了正确的地方。
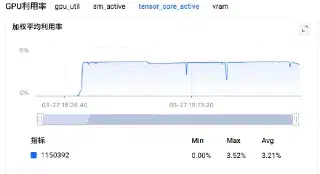
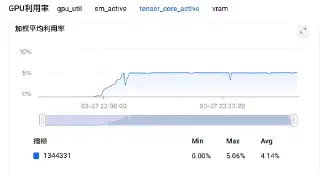
3.4 Listwise Squeeze:消除 per-item KV 重复
v3.0 的 stage-1 对 listwise 内每个 item 独立构建 KV,而同一请求内所有 item 共享相同的用户序列,造成大量重复计算与显存占用。
具体来说,假设一个请求带 N=300 个候选 item,stage-1 的 self-attention 在 v3.0 实现里实际上跑了 300 次完全一样的运算——同样的用户序列、同样的 attention 输出,重复打了 300 份。
Listwise Squeeze 实现思路:v3.1 引入 Listwise Squeeze:在 stage-1 先将序列在 user 维度折叠(去除 item 维重复),计算完成后在 stage-2 通过 kv_cache_repeats 展开还原给每个 item,显存占用与 batch 内 item 数解耦。
v3.0 流程: (B, N, L, D) ── stage1 self-attn ──→ (B, N, L, D) ─→ stage2
v3.1 流程: (B, L, D) ── stage1 self-attn ──→ (B, L, D) ── repeat ─→ stage2
↑ 一份 ↑ 一份计算 ↑ N 份
stage-1 的 self-attention 计算量从 $O(B \cdot N \cdot L^2 \cdot D)$ 降到 $O(B \cdot L^2 \cdot D)$,也就是直接除以 N(300),降低 2 个数量级。
为什么 v3.0 没这么做:v3.0 的实现里 stage-1 / stage-2 的接口约束了输入张量必须带 N 维度,重构这条接口涉及到 listwise 框架的核心数据流,是一个较重的工程。v3.1 借着 RM Padding 一起重构,正好把这两笔账一起算了。
3.5 GQA Triton FlashAttention 反向改造
已有的 lego 版本在 GQA 的反向逻辑上存在不适配的 bug(特判 MLU 逻辑误生效)。修复方式是在图内重写正确的梯度反传逻辑,核心是处理多头 GQA 的 dk/dv 归约:
def _flash_attention_fwd_varlen_grad(self, op, *grad):
dq, dk, dv = lego_ops.flash_attention_bwd_varlen(...)
head_group = q_head // kv_head
def reduce_fn():
new_dk = tf.reduce_sum(
tf.reshape(dk, [k_len, kv_head, head_group, qk_dim]), axis=2)
new_dv = tf.reduce_sum(
tf.reshape(dv, [k_len, kv_head, head_group, v_dim]), axis=2)
return new_dk, new_dv
dk, dv = tf.cond(head_group > 1, reduce_fn, no_reduce_fn)
return (dq, dk, dv) + (None,) * 6
当 head_group > 1(即 Q-head > KV-head)时,对 dk/dv 在 head_group 维度做 reduce_sum,将梯度正确归约到 KV head 数量。
梯度归约的数学含义:在前向计算中,一组 Q heads 共享一组 K, V。这意味着 $L = \sum_i \text{loss}(q_i, k_g, v_g)$,其中 $g$ 是该组对应的 KV head。求 $\frac{\partial L}{\partial k_g}$ 时,要把所有共享这组 KV 的 query head 的梯度加起来。这就是 reduce_sum 的来源。
为什么不能简单用 Q-head 数量的梯度直接当 KV-head 梯度:那样相当于多次重复同一组 KV 的梯度,会让 KV 学习速率"虚拟放大" head_group 倍,训练完全发散。reduce_sum 是数学上唯一正确的归约方式。
4. Serving 效率优化:M-Falcon
4.1 原始方案的瓶颈:xmatmul 的碎片化调度
stage-2 cross-attention 原先使用 xmatmul 实现:每个 candidate item 独立调度一次 kernel,中间结果写回 GPU global memory,无法使用 FlashAttention 的 IO 融合优化。在序列较长时,这种碎片化调度模式成为推理 latency 的主要瓶颈。
问题的症结在于:每个 item 的 attention 计算规模太小(单个 item query × 2K user sequence),无法充分填满 GPU 的 Tensor Core;而 kernel launch overhead 在高并发的推荐场景下显著累积。
具体看一组数据:在 v3.0 Serving Profile 里,stage-2 cross-attention 部分的 SM Tensor Core Active 只有 6.1%,远低于现代 GPU 应有的水平(理想区间 30%+)。也就是说,绝大部分 GPU 时间被花在了 kernel launch、memory bandwidth、scheduling 等"杂事"上,真正参与有效 matmul 的时间不到 1/15。
4.2 M-Falcon:拍平合并,单次 FlashAttention
核心思路:将所有 item 的 query token 拍平成一个序列,与用户序列 KV Cache 拼接,batchsize 变为 1(per user)。加上特殊的 Mask 控制可见性,整体送入 FlashAttention 做一次 kernel 计算。中间结果不再落回 global memory,降低 IO 开销。
xmatmul: item_1 query → attn(seq) → out_1
item_2 query → attn(seq) → out_2
... (N 次 kernel launch)
item_N query → attn(seq) → out_N
M-Falcon: [item_1 query, item_2 query, ..., item_N query, seq]
↓
upper triangular mask
↓
FlashAttention ← 1 次 kernel
↓
[out_1, out_2, ..., out_N]

三个关键设计:
① 上三角 Attention Mask 保证等价性
将多个 item 拍平到同一序列后,通过上三角矩阵 Mask(q_offset <= k_offset)确保:
- 每个 item query 能 attend 到完整用户历史序列
- item 之间不互相 attend,避免信息泄露
数学上,假设拍平后总序列长度 $L_{\text{total}} = N + L_{\text{seq}}$,前 $N$ 个 token 是 item query,后 $L_{\text{seq}}$ 个是用户序列。Attention mask 的设计:
$$ M_{ij} = \begin{cases} 0 & i \in [0, N), j \in [N, L_{\text{total}}) \\ 0 & i = j \text{ (item self-loop, 可选)} \\ -\infty & \text{otherwise} \end{cases} $$也就是 item query 只能 attend 到 user sequence,不能 attend 到其他 item,也不能 attend 到自己的过去(保持与 v3.0 等价性)。
计算结果与原始逐 item 独立计算完全数值等价。
② Unpad Merge 拼接
将拍平后的 item query KV 与用户历史 KV 通过 unpad_merge 操作拼接,构造统一的 cu_seqlens,交给 FlashAttention(mask_fn=3)单次 kernel 完成计算。
mask_fn=3 是 FlashAttention 提供的自定义 mask 路径,允许传入一个 mask 计算函数,在线计算 mask 而不是预先实例化整个 $L_{\text{total}} \times L_{\text{total}}$ 的 mask 矩阵——这对于 $L_{\text{total}} \approx 2000 + 300 = 2300$ 的场景,节省了 5MB+ 的 mask 存储。
③ 等价替换,无需重训
M-Falcon 前向结果与原始实现数值一致,可在不修改模型权重的前提下直接替换,零迁移成本。这一点在工程实践里非常关键——如果替换 attention 实现需要重训整个模型,那么从决策到上线的周期会拉长一倍以上。M-Falcon 的等价性保证了"先训练好再切实现"的范式,把训练和 serving 解耦。
4.3 Serving 综合收益
RM Padding + M-Falcon 双优化上线后:
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| Service QPS | ~271 req/s | ~534 req/s | +97% |
| SM Active | 55.5% | 62.0% | +6.5pp |
| SM Tensor Active | ~6.1% | ~7.3% | +~20% |
QPS 近乎翻倍,是本次效率优化最直观的线上收益。
为什么 SM Tensor Active 只升到 7.3%:精排 Serving 的天然约束是 batch_size 小(per user),即便用上 M-Falcon 把多个 item 拍平,总 token 数也只有 2K~2.5K 量级,远低于训练 batch 的 32K+ token。这个尺度下 Tensor Core 还达不到理想利用率。要进一步往上突破,需要把多个用户的请求一起 batch 起来——这是后续 V3.2 / V4 的方向。
5. Torch Rebase:跨框架迁移的工程实践
v3.1 同步完成了从 TensorFlow 到 PyTorch 的框架迁移(Torch Rebase),并完成离在线打平,作为后续迭代的 Torch 基线。
离在线打平的挑战:框架切换不仅是代码翻译,还涉及数值精度、算子实现差异、分布式训练行为等多个层面的对齐。团队整理了 step-by-step 的迁移操作手册,并开发了自动迁移对比工具,系统性地验证离线指标(AUC、UAUC)和在线指标的打平。
自动对比工具的核心机制:在每一层 forward 输出处插桩,把 TF 模型和 Torch 模型同时跑同一批样本,对比每层激活值的相对误差。设置一组阈值(例如 atol=1e-4, rtol=1e-3),任何一层超出阈值就触发报警,定位到具体哪个算子产生了精度漂移。这种自动化对比让"逐层调试"不再依赖工程师手工 print。
常见的精度漂移源:
- 算子默认精度:TF 默认 float32,Torch 默认 float32 但某些算子(如 LayerNorm)在 cuDNN 下可能 fallback 到 mixed precision,需要显式控制。
- 算子语义微差:TF 的
softmax和 Torch 的softmax在数值稳定性实现上有细微差别(TF 减最大值后再减最小值,Torch 直接减最大值)。在长序列下这种差别可能放大。 - embedding 初始化:TF 默认 truncated_normal,Torch 默认 normal,需要统一。
- 优化器更新顺序:TF 的
apply_gradients和 Torch 的optimizer.step()在分布式 all-reduce 时机上有差别。
Serving 打平:针对 Serving 框架差异,完成了内部 Serving 框架的 Torch 模型接入,确保推理路径与 TensorFlow 版本数值一致。
6. 模型工程参数演进
| 参数 | v3.0 | v3.1 | 变化 |
|---|---|---|---|
| NN Params | 165M | 396M | +140% |
| d_model | 384 | 512 | +33% |
| SeqFormer 层数 | 5 | 7 | +40% |
| 序列长度 | 1K | 2K | +100% |
| KV Heads | 8 | 2 | -75%(GQA 节省显存) |
| Training instance/s | 48K | 25K | -47%(更大模型 + 更长序列) |
| GPU SMA | 82 | 80 | -2pp |
| Tensor Core Active | 9.9% | 5.1% | -4.8pp(序列扩展后 kernel 变小) |
注:训练吞吐下降是序列 2× + 模型 2.4× 参数量带来的必然代价,通过 RM Padding 和 Listwise Squeeze 部分对冲(原始方案会更低)。
为什么 Tensor Core Active 下降了:v3.0 的层数少(5 层)、序列短(1K),attention kernel 单次计算规模较大,更容易打满 Tensor Core。v3.1 的层数多(7 层),每层 kernel 的相对规模变小,Tensor Core 利用率自然下降。这是 Scaling 必然带来的代价,但通过 GQA + RM Padding 把绝对吞吐拉回来了。
显存账面分析:理论上序列从 1K 到 2K,KV cache 显存翻倍;模型从 165M 到 396M,参数显存提升 2.4×;7 层 vs 5 层,激活显存提升 1.4×。如果不做任何优化,整体显存需要 ~5×。但实际上 v3.1 在同一卡型下完成训练,关键就是:
- GQA 把 KV 显存压缩 4×。
- Listwise Squeeze 把 stage-1 显存压缩 N=300×(item 维度折叠)。
- RM Padding 把激活显存压缩 ~2.5×(去掉 padding 浪费)。
三者叠加,把"理论上需要 5× 显存"压缩回了"原本的水平"。
7. 线上 A/B 实验结果
实验配置:12 完整天,每组 40% 流量,共 80%;核心模块覆盖 Mall | OC | CART | Trade Path | Diversion | Category Tab。
7.1 核心业务指标
泛商城(General Mall):
| 指标 | 变化 |
|---|---|
| GMV/user | +1.0175% |
| uv_ctcvr | +0.4986% |
| main_order/user | +1.3642% |
| sub_order/user | +1.9207% |
| click/user | +1.277% |
| uv_ctr | +0.2817% |
Mall Feeds:
| 指标 | 变化 |
|---|---|
| GMV/user | +0.5894% |
| click/user | +1.4431% |
| uv_ctr | +0.2607% |
大盘: 人均支付成功 sku 单数(剔除异常单)+0.4715%
7.2 多维度收益
- 多样性:曝光四级类目数 +1.094%,点击四级类目数 +1.423%
- 发现性:发现性流量 PV 占比 +0.641%,人均发现性点击四级类目宽度 +1.878%
- 冷启动:0 单商品点击 PV 人均 +1.337%
- 首购:当日首购类目 +1.126%
7.3 ROI
- ROI +0.24%
- 综合(引入 FP16 等训推优化后)ROI +0.11%,增量 ROI 277
7.4 业务收益的归因分析
把 +1.02% GMV/user 拆开看,可以看到几个值得关注的现象:
- click/user (+1.277%) 与 GMV/user (+1.02%) 同步上升,且 click/user 涨幅更大——说明模型把更多样的内容推到了用户面前,用户点击意愿提升,最终成交也跟着上去。这是一种"健康"的提升,而不是单纯靠"挑出最贵的 item"压榨成交。
- 多样性指标(曝光/点击四级类目数 +1.1% / +1.4%)正向,说明 2K 序列+丰富特征带来的"长期兴趣建模能力"真的让模型看到了更宽的兴趣面,而不是把所有用户都收敛到几个热门类目。
- 冷启动指标 +1.337%、首购 +1.126%,说明长序列对"新用户/新场景"也有显著帮助——这与直觉相反的发现,但合理:长序列里有更多的"探索性 click",模型可以借助这些信号判断"这个用户在哪些方向是新手,哪些方向是老手"。
8. 工程思考与经验总结
8.1 效率优化是 Scaling 的先决条件
v3.1 的四条主线并非独立并行,而是有明确的因果依赖:先解决训练/Serving 效率问题,才有预算做结构 Scaling Up。RM Padding 和 Listwise Squeeze 释放的显存与算力预算,直接使能了 d_model=512、SeqFormer 7 层的扩展;M-Falcon 的 QPS 翻倍则为更大模型的 Serving 成本提供了缓冲。
这说明在工业推荐场景下,模型 Scaling 不是单纯的参数堆叠,而是效率-容量的协同优化:每一轮效率提升都打开了新的容量空间,而容量提升带来的效果增益反过来验证了效率投入的价值。
类比看,LLM 的 Scaling Law 之所以能持续兑现,背后离不开 FlashAttention、PagedAttention、Continuous Batching 这一系列效率工具的不断推进。精排领域走的是同一条路——只是它的"效率瓶颈点"和 LLM 不完全一样,需要在序列长度、batch size、listwise 重复等维度上做特化。
8.2 GQA 的收益需要充分收敛才能显现
GQA 早期训练窗口的负向波动是一个值得注意的现象:在训练 0601-0630 阶段,8Q/2KV 配置 AUC 下降 -0.09,而到 1001-1031 阶段反转为 +0.04。贸然用早期 checkpoint 评判 GQA 的效果,会得出错误结论。
这一现象的底层逻辑:GQA 通过参数共享降低了 KV 的表达冗余,模型需要更多步数才能在降低的 KV 容量下学到足够的用户序列模式。早期表现弱不是模型的极限,而是还没充分收敛。
实操建议:
- 不要用早期 AB 实验评判 GQA。GQA 的收敛速度比 MHA 慢,前 10B-50B 样本的 AB 数据基本没有参考价值。
- 观察 AB 收益曲线的斜率。如果 GQA 相对 MHA 的差距在持续缩小(甚至反超),说明它在正确的方向上;如果差距长期稳定,可能模型容量上限差异是固定的。
- 结合服务端收益做总账。即便 GQA 在质量上和 MHA 持平,光是显存节省 4× 带来的显存预算释放,就足以支持其它结构改动,整体仍是大幅净收益。
8.3 TruncatedNormal 初始化是加宽的稳定器
直接从 384 加宽到 512/768 而不调整初始化,会导致输出方差随宽度比例放大,激活饱和,训练不稳。TruncatedNormal std=0.02 的选择并不神秘——它的本质是让每层输出的方差尺度与宽度无关(通过更小的 std 对抗 fan-in 增大带来的方差膨胀)。实践中 std=0.02 是一个经验上相对保守、稳定性好的选择。
更进一步的视角:精排模型相比 LLM 有一个特殊点——它的训练数据是不停滚动的(每天新到样本),所以"训练初期的稳定性"特别重要——如果开训前几小时就走偏,整个 daily refresh 周期就被毁了。TruncatedNormal 在这种"不能容忍长尾不稳定"的场景下尤其合适。
8.4 Fid 统一 Slice 的收益来自信息流通
同一个 slot 的特征和序列用不同 slice 的问题,本质是人为制造了 embedding 空间的割裂。Transformer 的 self-attention 本来可以直接捕获 Target item 和序列 item 在同一特征维度上的相似性,但两段独立 embedding 使得"同一个特征值"在特征侧和序列侧有两套不同的表示,Attention 需要额外的参数容量来学习这两套表示之间的对应关系。统一 Slice 相当于给模型做了"对齐初始化",消除了这层多余的学习负担。
8.5 RM Padding 的"看似简单实则复杂"
RM Padding 的核心思想用一句话就能说完:“去掉 padding,把所有有效 token 拼成一个一维张量”。但实际工程实现里,它牵动了:
- 算子层:所有 per-token 算子都要补 ragged 版本。
- 图编译层:XLA / Triton 的融合规则必须重写。
- NaN 处理:长度为 0 的样本暴露了原本被 mask 掩盖的 bug。
- 训练超参:batch 内有效 token 数变成动态的,learning rate / gradient accumulation 步数都要重新调校。
- Profile 工具:原本看 SM Active 就能判断 GPU 利用率,现在要看 Tensor Core Active 才更准。
每一个点单独看都不困难,但全部走通需要工程团队对训练栈的完整 ownership。这也是为什么 RM Padding 在 LLM 已经普及多年,但精排场景到现在才广泛落地的原因。
8.6 M-Falcon 的"等价替换"价值
M-Falcon 最被低估的特性其实是"等价替换"——不需要重训模型,可以直接 swap 掉旧的 xmatmul 实现。这意味着:
- 训练侧无感:不用重新训练,沉没成本是零。
- 灰度可控:上线 1% → 10% → 50% → 100% 的灰度过程中,任何时候发现问题都能即时回滚。
- 风险可量化:一次只改一个变量(attention 实现),AB 收益完全可以归因到 M-Falcon 自身。
这种"等价替换"思维在工业系统里非常重要——它把"模型创新"和"工程优化"解耦,两条线可以并行推进。
8.7 未来方向
- 序列进一步扩展:2K → 4K 甚至更长,需要更激进的效率优化(稀疏 Attention、进一步压缩 KV)。在 4K 长度下,全量 attention 会重新成为瓶颈,必须引入 Sliding Window / Sparse Attention / Linear Attention 等近似机制。
- M-Falcon 泛化:将拍平合并策略推广到更多 cross-attention 场景(例如 user × ad、user × creator 的多 target 联合建模)。
- 模型 Scaling 继续:d_model=512 → 768/1024,SeqFormer 7 → 9/12 层。这一步的关键不是模型本身能否训出来,而是显存和 Serving 延迟能否给得起。
- Foundation Model 范式迁移:将 Pretrain → Posttrain → SFT 的多阶段训练范式引入精排,复用召回层的 Foundation Model 权重。这一步可能是精排下一波"质变级"提升的关键路径——把精排从"专项任务"变成"通用智能下游适配"。
- 多模态信号引入:用户行为序列里其实可以注入图片 embedding、文本 embedding 等多模态信号。这一步的难点在于多模态信号的"长期 freshness"——商品图片可能更新,模型需要应对动态信号。
- 在线学习与实时更新:现行 daily refresh 的训练周期还是太慢。把 KV cache 这一类与"用户最新行为"强相关的部分在线刷新,是延迟和 freshness 之间的合理 tradeoff。
参考文献
- Ainslie, J., et al. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv:2305.13245
- Dao, T., et al. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS 2022.
- Dao, T., et al. (2023). FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. ICLR 2024.
- Zhang, B., & Sennrich, R. (2019). Root Mean Square Layer Normalization. NeurIPS 2019.
- Press, O., et al. (2024). SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling. arXiv:2312.15166
- Shazeer, N. (2020). GLU Variants Improve Transformer. arXiv:2002.05202
- Zhai, S., et al. (2023). Scaling Vision Transformers to 22 Billion Parameters. ICML 2023.
- Henry, A., et al. (2020). Query-Key Normalization for Transformers. EMNLP Findings 2020.
- Shazeer, N. (2019). Fast Transformer Decoding: One Write-Head is All You Need. arXiv:1911.02150
- Pope, R., et al. (2023). Efficiently Scaling Transformer Inference. MLSys 2023.
- Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS 2017.
- Zhou, G., et al. (2018). Deep Interest Network for Click-Through Rate Prediction. KDD 2018.
- Zhou, G., et al. (2019). Deep Interest Evolution Network for Click-Through Rate Prediction. AAAI 2019.
- Pi, Q., et al. (2020). Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction. CIKM 2020.
- Chen, Q., et al. (2019). Behavior Sequence Transformer for E-commerce Recommendation in Alibaba. DLP-KDD 2019.
- Kang, W. C., & McAuley, J. (2018). Self-Attentive Sequential Recommendation. ICDM 2018.
- Sun, F., et al. (2019). BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. CIKM 2019.
- Touvron, H., et al. (2023). LLaMA 2: Open Foundation and Fine-Tuned Chat Models. arXiv:2307.09288.

字节推荐广告算法工程师,专注电商推荐系统。电商广告模型 → 电商推荐模型,兴趣方向:模型结构 Scale Up、序列建模、首点归因、GMV 回归建模。
日常分享搜广推论文 & LLM 笔记,以及自己做的一些小工具和尝试过程。
🔥 欢迎加入 TT 电商推荐团队,期待共建业界领先的推荐系统,完成 LLM 的清晰落地!内推通道 →